Welcome! Meet our Python Code Assistant, your new coding buddy. Why wait? Start exploring now!
In this guide, you'll learn how to remove metadata from Portable Document Formats (PDFs). Metadata refers to additional information embedded within a file, including details like author name, creation date, editing history, and more.
Someone might want to remove metadata from a PDF for privacy or security reasons, as metadata can reveal sensitive information about the document's creator, editing history, or location. Metadata removal can help maintain confidentiality in sensitive documents, protecting individuals or organizations from potential privacy breaches.
Removing metadata can also reduce file size, making it easier to share or upload without carrying unnecessary information.
We'll be achieving this using Python's PyPDF2. Before we go into the code, let me show you how you can extract metadata from a PDF in the first place.
Using this online PDF metadata extractor tool, we'll upload a PDF and extract its metadata. It is free:
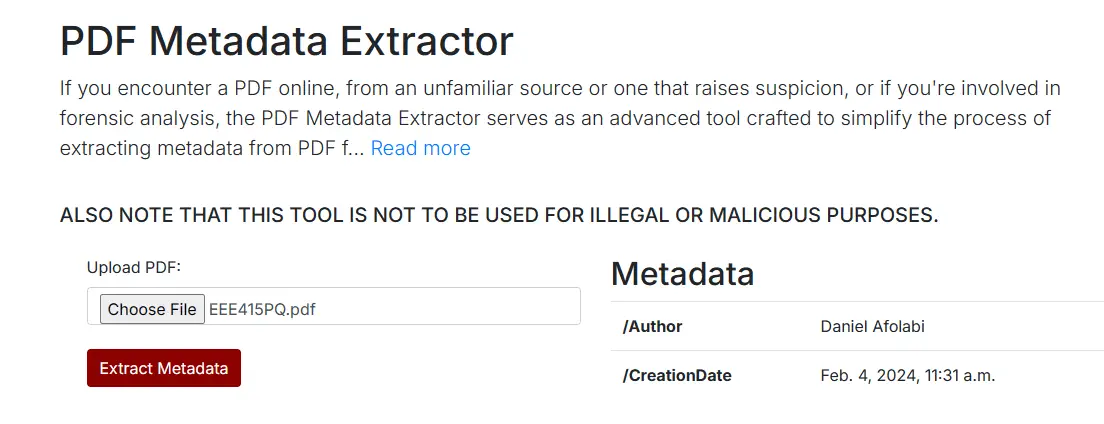
We can see the metadata of the EEE415PQ.pdf document. Using that tool, we can now see the author of the PDF and the creation date.
You can also check this tutorial for extracting metadata from PDFs using Python.
Depending on the scenario, these two pieces of information are enough to solve a 30-year-old mystery - believe it or not, we've seen similar occurrences in the past. I am not encouraging illegal activities with the backing of deleting metadata. I am only trying to show you the importance of metadata and why an individual may want to eliminate it.
Now, let's write a Python script to do just that. We'll start by installing PyPDF2:
$ pip install PyPDF2As always, open a Python file, and name it meaningfully, like remove_pdf_metadata.py and follow along.
Next, we import PyPDF2 and create a function to remove the metadata from a given PDF:
import PyPDF2
def remove_metadata(pdf_file):
# Open the PDF file.
with open(pdf_file, 'rb') as file:
reader = PyPDF2.PdfReader(file)
# Check if metadata exists.
if reader.metadata is not None:
print("Metadata found in the PDF file.")
# Create a new PDF file without metadata.
writer = PyPDF2.PdfWriter()
# Copy pages from the original PDF to the new PDF.
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
writer.add_page(page)
# Open a new file to write the PDF without metadata.
new_pdf_file = f"{pdf_file.split('.')[0]}_no_metadata.pdf"
with open(new_pdf_file, 'wb') as output_file:
writer.write(output_file)
print(f"PDF file without metadata saved as '{new_pdf_file}'.")
else:
print("No metadata found in the PDF file.")
# Specify the path to your PDF file.
pdf_file_path = "EEE415PQ.pdf"
# Call the function to remove metadata.
remove_metadata(pdf_file_path)This remove_metatdata() function uses the PyPDF2 library to remove metadata from a PDF file. It takes a PDF file path as input, opens the file, and checks if it contains metadata. If metadata exists, it creates a new PDF file by copying the pages from the original file but excluding the metadata. The resulting PDF file is saved with the suffix _no_metadata appended to the original file name. If no metadata is found, it prints a message indicating so.
Please do not forget to replace EEE415PQ.pdf with your own PDF.
Here's my result when I run it:
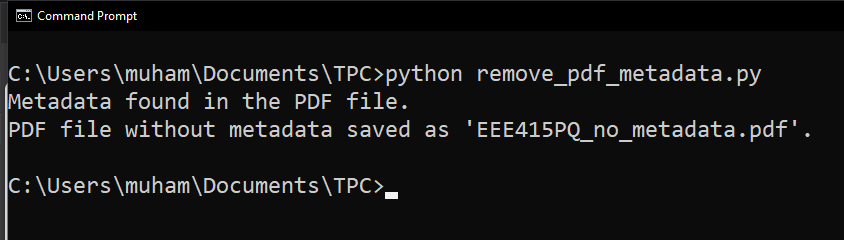
After running the code, our program tells us that our PDF without metadata is EEE415PQ_no_metadata.pdf. This will be in your working directory.
Now, let's go back to our online tool we used earlier, and upload this EEE415PQ_no_metadata.pdf and try to extract metadata from it. Bear in mind the content of the EEE415PQ_no_metadata.pdf PDF and EEE415PQ.pdf are the same (with the exception of the metadata).
Results:
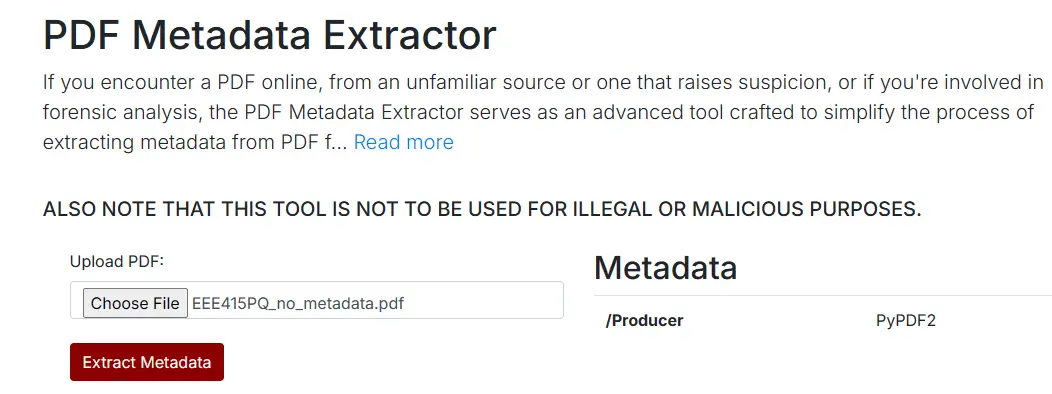
We can see that the only 'metadata' we're getting now is PyPDF2. This is because PyPDF2 appends that to every PDF it creates. I don't know about you, but I'd rather adversaries see this, than the author and the creation date when I'm covering my tracks.
There you have it! Now you have the exact same PDFs in terms of content, but one is more secure (not revealing sensitive information) than the other.
Note: If you feed the EEE415PQ_no_metadata.pdf back to our program, it'll still tell you metadata exists. This is because of the /Producer PyPDF2 entry, which you shouldn't worry about. If you pass a PDF that has no metadata whatsoever, our program will notify you that no metadata exists.
Additionally, if you want to learn to extract metadata with Python, check out this tutorial.
Get the complete code of this tutorial here.
I hope you enjoyed this one. Till next time!
Found the article interesting? You'll love our Python Code Generator! Give AI a chance to do the heavy lifting for you. Check it out!
View Full Code Switch My Framework



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!