Juggling between coding languages? Let our Code Converter help. Your one-stop solution for language conversion. Start now!
Introduction
YouTube videos often contain valuable information, but watching an entire video can be time-consuming. What if you could extract the transcript of a video and generate a concise summary? In this tutorial, we will build a Python program that does exactly that! Using pytube to fetch video details and YouTubeTranscriptApi to get transcripts, we will process the text using NLTK and generate a meaningful summary.
By the end of this tutorial, you will learn how to:
- Extract the transcript from a YouTube video
- Process and clean the text
- Summarize the transcript using word frequency analysis with two options: using the tranditional
NLTKlibrary and using LLMs via an API. - Display the results in a nicely formatted way
Installing Required Packages
Before writing the script, ensure you have the required dependencies installed. You can install them using pip:
pytube: Fetches video metadatayoutube-transcript-api: Retrieves video transcriptsnltk: Performs natural language processing (NLP)colorama: Adds color to terminal outputopenaifor AI-based text summarization using OpenRouter's API.
Obtaining OpenRouter API Key
Also, we’re going to be using an OpenAI API-compatible library from OpenRouter. So head on to the website, sign up if you don’t already have an account and create an API key. It’s pretty straightforward. The specific model we’ll be using is Mistral: Mistral Small 3.1 24B (free). It’s a free model so you don’t have to pay. For more insights on how to use the API, just read through the overview section.
After grabbing your API key, open up a Python file, name it meaningfully like youtube_transcript_summarizer.py and follow along.
The Summarization Script
First, we import the necessary libraries for this project.
import os
import re
import nltk
import pytube
import youtube_transcript_api
from youtube_transcript_api import YouTubeTranscriptApi
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.probability import FreqDist
from heapq import nlargest
from urllib.parse import urlparse, parse_qs
import textwrap
from colorama import Fore, Back, Style, init
from openai import OpenAI
The script begins by importing necessary libraries:
osfor terminal width detection.refor regular expressions.heapqfor extracting the most significant sentences.textwrapfor text formatting.
# Initialize colorama for cross-platform colored terminal output
init(autoreset=True)Next, colorama.init(autoreset=True) is called to enable cross-platform color support, ensuring that color formatting resets automatically after each output. Check this article if you're interested to learn more about Colorama.
# Download necessary NLTK data
nltk.download('punkt_tab', quiet=True)
nltk.download('punkt', quiet=True)
nltk.download('stopwords', quiet=True)The script downloads necessary nltk resources (punkt for tokenization and stopwords for filtering common words), ensuring they are available without user intervention.
# Initialize OpenAI client
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="API-KEY HERE!",
)
openai.OpenAI(api_key=API_KEY) initializes the OpenRouter API client, which will be later used for AI-driven summarization. Please include your API key there.
def extract_video_id(youtube_url):
"""Extract the video ID from a YouTube URL."""
parsed_url = urlparse(youtube_url)
if parsed_url.netloc == 'youtu.be':
return parsed_url.path[1:]
if parsed_url.netloc in ('www.youtube.com', 'youtube.com'):
if parsed_url.path == '/watch':
return parse_qs(parsed_url.query)['v'][0]
elif parsed_url.path.startswith('/embed/'):
return parsed_url.path.split('/')[2]
elif parsed_url.path.startswith('/v/'):
return parsed_url.path.split('/')[2]
# If no match found
raise ValueError(f"Could not extract video ID from URL: {youtube_url}")
The extract_video_id(youtube_url) function extracts a YouTube video ID from various URL formats, including standard, shortened (youtu.be), and embedded formats, raising an error if the ID cannot be determined.
def get_transcript(video_id):
"""Get the transcript of a YouTube video."""
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return ' '.join([entry['text'] for entry in transcript])
except Exception as e:
return f"Error retrieving transcript: {str(e)}."
The get_transcript(video_id) function retrieves the transcript of a video using YouTubeTranscriptApi.get_transcript(video_id), handling errors gracefully by returning an error message if the transcript is unavailable.
def summarize_text_nltk(text, num_sentences=5):
"""Summarize text using frequency-based extractive summarization with NLTK."""
if not text or text.startswith("Error") or text.startswith("Transcript not available"):
return text
# Tokenize the text into sentences and words
sentences = sent_tokenize(text)
# If there are fewer sentences than requested, return all sentences
if len(sentences) <= num_sentences:
return text
# Tokenize words and remove stopwords
stop_words = set(stopwords.words('english'))
words = word_tokenize(text.lower())
words = [word for word in words if word.isalnum() and word not in stop_words]
# Calculate word frequencies
freq = FreqDist(words)
# Score sentences based on word frequencies
sentence_scores = {}
for i, sentence in enumerate(sentences):
for word in word_tokenize(sentence.lower()):
if word in freq:
if i in sentence_scores:
sentence_scores[i] += freq[word]
else:
sentence_scores[i] = freq[word]
# Get the top N sentences with highest scores
summary_sentences_indices = nlargest(num_sentences, sentence_scores, key=sentence_scores.get)
summary_sentences_indices.sort() # Sort to maintain original order
# Construct the summary
summary = ' '.join([sentences[i] for i in summary_sentences_indices])
return summaryThe summarize_text_nltk(text, num_sentences=5) function processes the transcript by tokenizing it into sentences, filtering out stopwords, computing word frequencies, and scoring sentences based on their significance using nltk. It selects the top num_sentences highest-scoring sentences and returns them in their original order.
def summarize_text_ai(text, video_title, num_sentences=5):
"""Summarize text using the Mistral AI model via OpenRouter."""
if not text or text.startswith("Error") or text.startswith("Transcript not available"):
return text
# Truncate text if it's too long (models often have token limits)
max_chars = 15000 # Adjust based on model's context window
truncated_text = text[:max_chars] if len(text) > max_chars else text
prompt = f"""Please provide a concise summary of the following YouTube video transcript.
Title: {video_title}
Transcript:
{truncated_text}
Create a clear, informative summary that captures the main points and key insights from the video.
Your summary should be approximately {num_sentences} sentences long.
"""
try:
completion = client.chat.completions.create(
model="mistralai/mistral-small-3.1-24b-instruct:free",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
)
return completion.choices[0].message.content
except Exception as e:
return f"Error generating AI summary: {str(e)}"This function generates a summary using OpenRouter's mistral model. It follows these steps:
- Truncates the transcript if it exceeds 15000 characters to avoid API errors.
- Constructs a prompt with the video title and transcript.
- Calls
openai.chat.completions.create()to generate a summary. - Returns the AI-generated summary or an error message.
Each LLM has its own context window, for this one, it has 96,000 tokens at the time of writing this article, which is roughly ~300k characters, but to avoid overloading the free API, I'm omitting anything that exceeds 15k.
def summarize_youtube_video(youtube_url, num_sentences=5):
"""Main function to summarize a YouTube video's transcription."""
try:
video_id = extract_video_id(youtube_url)
transcript = get_transcript(video_id)
# Get video title for context
try:
yt = pytube.YouTube(youtube_url)
video_title = yt.title
except Exception as e:
video_title = "Unknown Title"
# Generate both summaries
print(Fore.YELLOW + f"Generating AI summary with {num_sentences} sentences...")
ai_summary = summarize_text_ai(transcript, video_title, num_sentences)
print(Fore.YELLOW + f"Generating NLTK summary with {num_sentences} sentences...")
nltk_summary = summarize_text_nltk(transcript, num_sentences)
return {
"video_title": video_title,
"video_id": video_id,
"ai_summary": ai_summary,
"nltk_summary": nltk_summary,
"full_transcript_length": len(transcript.split()),
"nltk_summary_length": len(nltk_summary.split()),
"ai_summary_length": len(ai_summary.split()) if not ai_summary.startswith("Error") else 0
}
except Exception as e:
return {"error": str(e)}The summarize_youtube_video(youtube_url, num_sentences=5) function combines the previous steps: it extracts the video ID, retrieves the transcript, summarizes it, and fetches video metadata (title, author, length, publish date, and views) using pytube.YouTube(youtube_url). It returns a dictionary containing the video title, summary, and transcript statistics.
def format_time(seconds):
"""Convert seconds to a readable time format."""
hours, remainder = divmod(seconds, 3600)
minutes, seconds = divmod(remainder, 60)
if hours > 0:
return f"{hours}h {minutes}m {seconds}s"
elif minutes > 0:
return f"{minutes}m {seconds}s"
else:
return f"{seconds}s"
The format_time(seconds) function converts a given number of seconds into a human-readable format like "2h 30m 15s".
def format_number(number):
"""Format large numbers with commas for readability."""
return "{:,}".format(number)The format_number(number) function formats large numbers with commas (e.g., 1234567 → 1,234,567).
def print_boxed_text(text, width=80, title=None, color=Fore.WHITE):
"""Print text in a nice box with optional title."""
wrapper = textwrap.TextWrapper(width=width-4) # -4 for the box margins
wrapped_text = wrapper.fill(text)
lines = wrapped_text.split('\n')
# Print top border with optional title
if title:
title_space = width - 4 - len(title)
left_padding = title_space // 2
right_padding = title_space - left_padding
print(color + '┌' + '─' * left_padding + title + '─' * right_padding + '┐')
else:
print(color + '┌' + '─' * (width-2) + '┐')
# Print content
for line in lines:
padding = width - 2 - len(line)
print(color + '│ ' + line + ' ' * padding + '│')
# Print bottom border
print(color + '└' + '─' * (width-2) + '┘')
The print_boxed_text(text, width=80, title=None, color=Fore.WHITE) function prints text inside a nicely formatted box with optional color and title.
def print_summary_result(result, width=80):
"""Print the summary result in a nicely formatted way."""
if "error" in result:
print_boxed_text(f"Error: {result['error']}", width=width, title="ERROR", color=Fore.RED)
return
# Terminal width
terminal_width = width
# Print header with video information
print("\n" + Fore.CYAN + "=" * terminal_width)
print(Fore.CYAN + Style.BRIGHT + result['video_title'].center(terminal_width))
print(Fore.CYAN + "=" * terminal_width + "\n")
# Video metadata section
print(Fore.YELLOW + Style.BRIGHT + "VIDEO INFORMATION".center(terminal_width))
print(Fore.YELLOW + "─" * terminal_width)
# Two-column layout for metadata
col_width = terminal_width // 2 - 2
# Row 3
print(f"{Fore.GREEN}Video ID: {Fore.WHITE}{result['video_id']:<{col_width}}"
f"{Fore.GREEN}URL: {Fore.WHITE}https://youtu.be/{result['video_id']}")
print(Fore.YELLOW + "─" * terminal_width + "\n")
# AI Summary section
ai_compression = "N/A"
if result['ai_summary_length'] > 0:
ai_compression = round((1 - result['ai_summary_length'] / result['full_transcript_length']) * 100)
ai_summary_title = f" AI SUMMARY ({result['ai_summary_length']} words, condensed {ai_compression}% from {result['full_transcript_length']} words) "
print(Fore.GREEN + Style.BRIGHT + ai_summary_title.center(terminal_width))
print(Fore.GREEN + "─" * terminal_width)
# Print the AI summary with proper wrapping
wrapper = textwrap.TextWrapper(width=terminal_width-4,
initial_indent=' ',
subsequent_indent=' ')
# Split AI summary into paragraphs and print each
ai_paragraphs = result['ai_summary'].split('\n')
for paragraph in ai_paragraphs:
if paragraph.strip(): # Skip empty paragraphs
print(wrapper.fill(paragraph))
print() # Empty line between paragraphs
print(Fore.GREEN + "─" * terminal_width + "\n")
# NLTK Summary section
nltk_compression = round((1 - result['nltk_summary_length'] / result['full_transcript_length']) * 100)
nltk_summary_title = f" NLTK SUMMARY ({result['nltk_summary_length']} words, condensed {nltk_compression}% from {result['full_transcript_length']} words) "
print(Fore.MAGENTA + Style.BRIGHT + nltk_summary_title.center(terminal_width))
print(Fore.MAGENTA + "─" * terminal_width)
# Split NLTK summary into paragraphs and wrap each
paragraphs = result['nltk_summary'].split('. ')
formatted_paragraphs = []
current_paragraph = ""
for sentence in paragraphs:
if not sentence.endswith('.'):
sentence += '.'
if len(current_paragraph) + len(sentence) + 1 <= 150: # Arbitrary length for paragraph
current_paragraph += " " + sentence if current_paragraph else sentence
else:
if current_paragraph:
formatted_paragraphs.append(current_paragraph)
current_paragraph = sentence
if current_paragraph:
formatted_paragraphs.append(current_paragraph)
# Print each paragraph
for paragraph in formatted_paragraphs:
print(wrapper.fill(paragraph))
print() # Empty line between paragraphs
print(Fore.MAGENTA + "─" * terminal_width + "\n")The print_summary_result(result, width=80) function displays the final summary result in a structured format. It prints a header with the video title, metadata, and the summarized transcript (for both “AI” and NLTK) with appropriate formatting and spacing. If an error occurs, it prints an error message in a red box.
if __name__ == "__main__":
# Get terminal width
try:
terminal_width = os.get_terminal_size().columns
# Limit width to reasonable range
terminal_width = max(80, min(terminal_width, 120))
except:
terminal_width = 80 # Default if can't determine
# Print welcome banner
print(Fore.CYAN + Style.BRIGHT + "\n" + "=" * terminal_width)
print(Fore.CYAN + Style.BRIGHT + "YOUTUBE VIDEO SUMMARIZER".center(terminal_width))
print(Fore.CYAN + Style.BRIGHT + "=" * terminal_width + "\n")
youtube_url = input(Fore.GREEN + "Enter YouTube video URL: " + Fore.WHITE)
num_sentences_input = input(Fore.GREEN + "Enter number of sentences for summaries (default 5): " + Fore.WHITE)
num_sentences = int(num_sentences_input) if num_sentences_input.strip() else 5
print(Fore.YELLOW + "\nFetching and analyzing video transcript... Please wait...\n")
result = summarize_youtube_video(youtube_url, num_sentences)
print_summary_result(result, width=terminal_width)The if __name__ == "__main__": block is the script’s entry point. It determines the terminal width for proper formatting, prints a welcome banner, prompts the user for a YouTube URL and desired summary length, then fetches and summarizes the video transcript before displaying the results.
Running the Script
Make sure to install the requirements first:
$ pip install pytube youtube-transcript-api nltk openai coloramaNow let’s run our code:
$ python youtube_transcript_summarizer.pyIt'll prompt you for the YouTube video URL.First result:
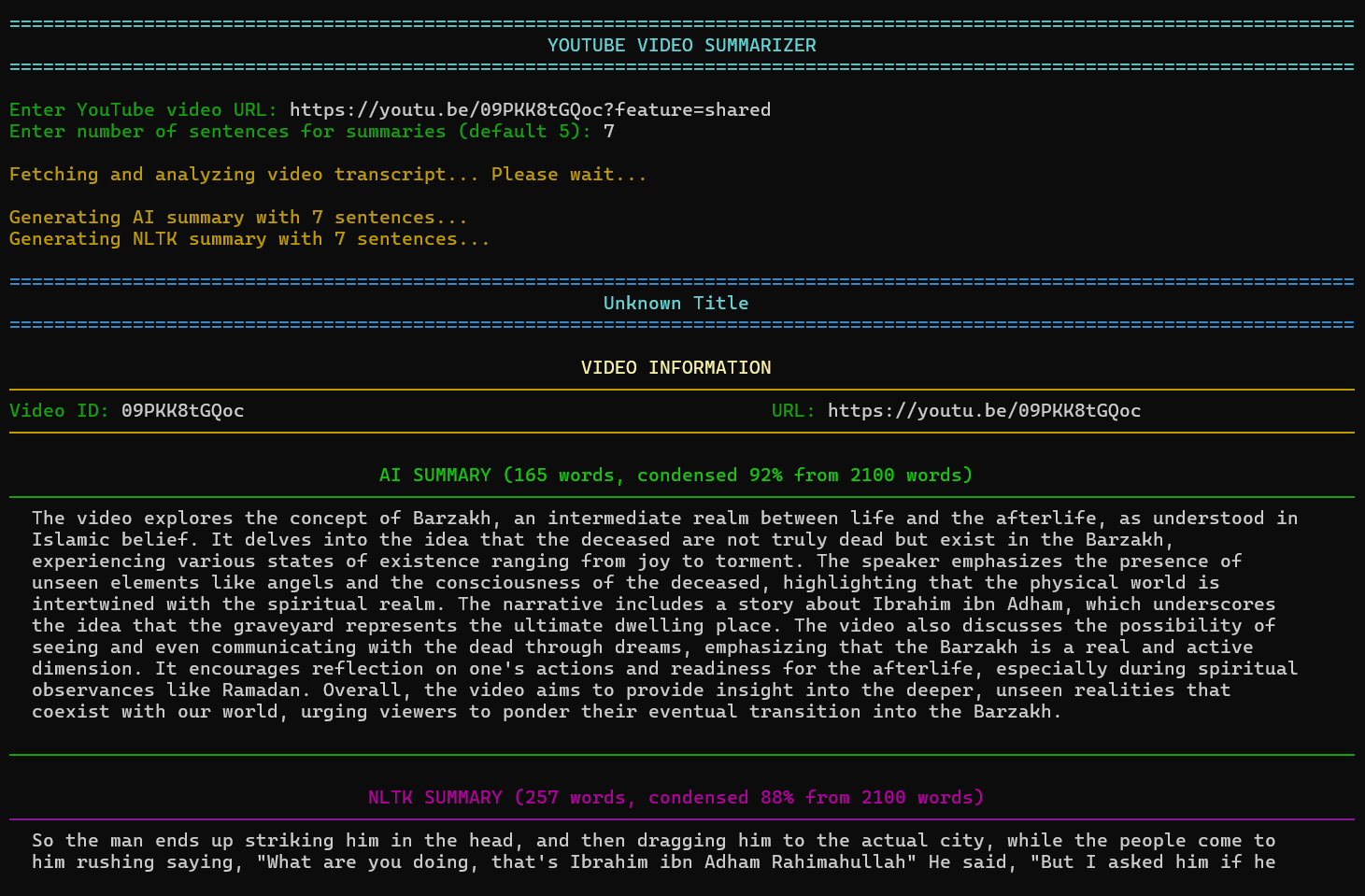
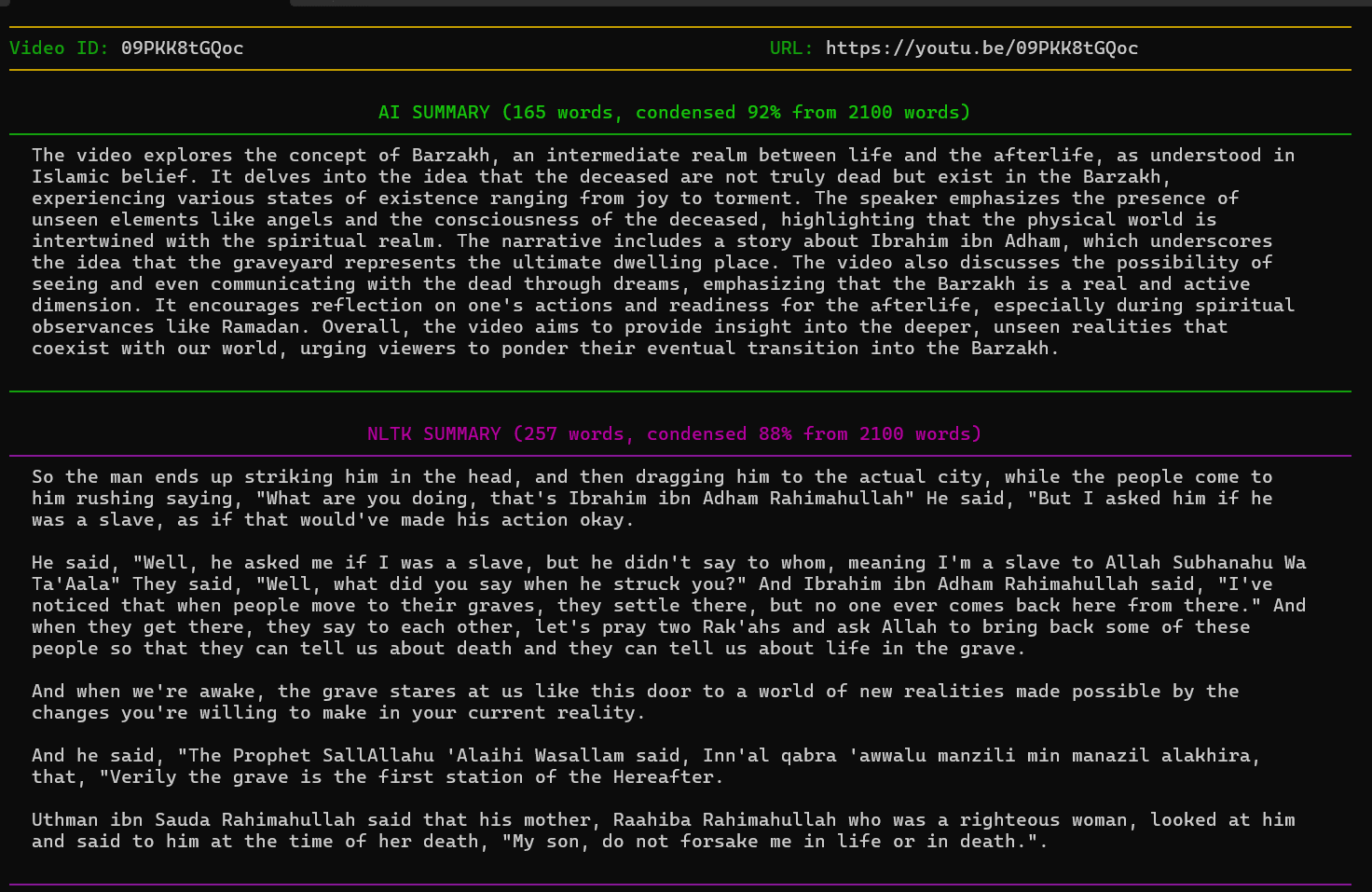
Notice that for the AI summary, out of 2100 words in the transcription, our program was able to summarize by approximately 92% to give us 165 words. We can see similar stats for the NLTK summary.
Important Note
The NLTK sentence-based summarization in our program works effectively when the transcript contains punctuation marks like commas and periods to define sentences. However, for transcripts lacking these punctuations, the entire transcript is typically returned.
The script is still beneficial because the AI summary does an excellent job regardless of whether punctuations are included or not. A good example is the transcript result we have above. Well summarised.
I’ll show you what I mean with an example:
When we run our code against another video that does not have punctuations in its transcription, we get:
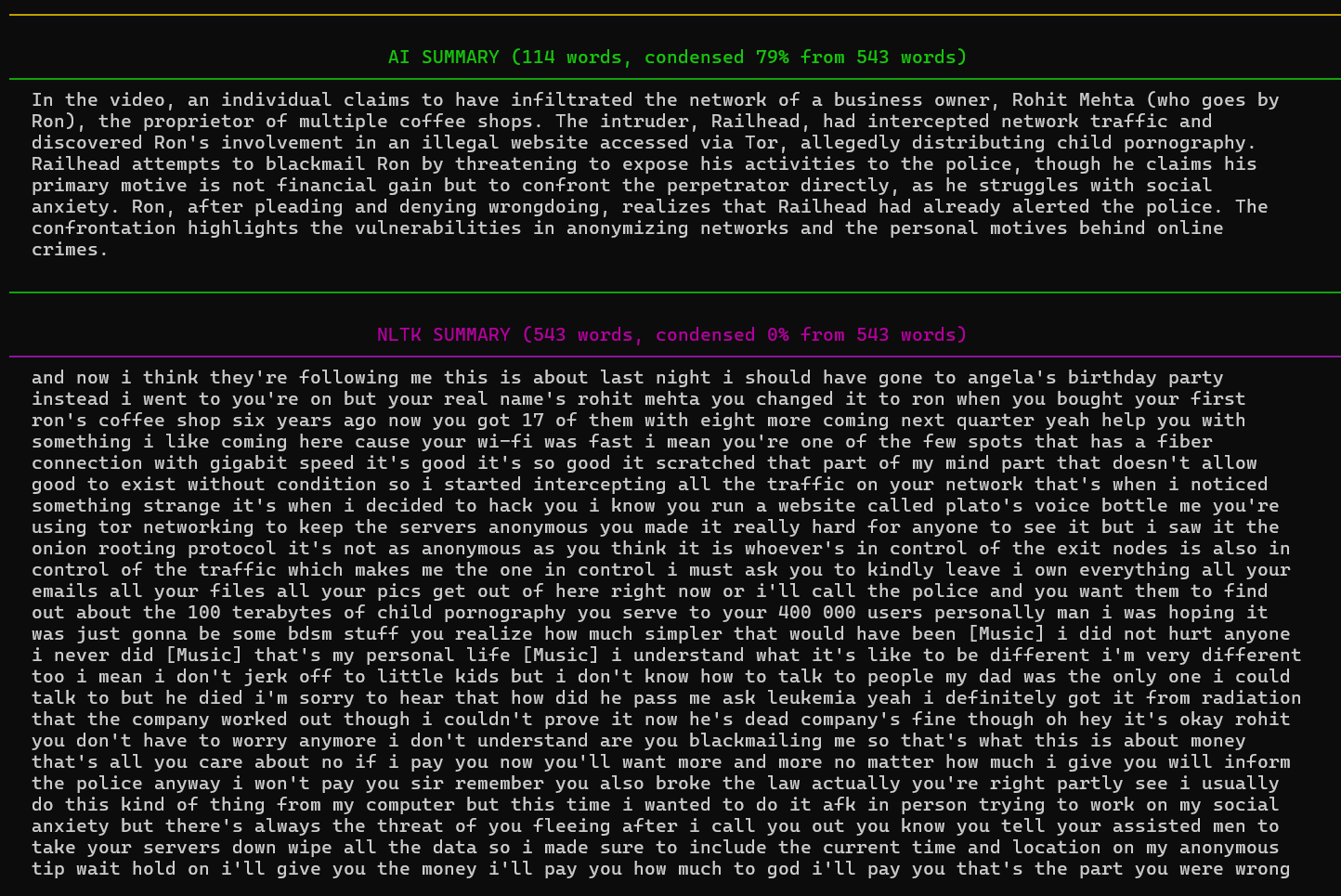
This is a transcript of a YouTube clip from Mr. Robot, featuring the scene where Elliot hacks Ron, the pedophile. Since the transcript lacks punctuation, NLTK results in 0% condensation, returning the entire transcript to the user but the Mistral model (LLM Summary) still does an excellent job.
Limitations
While the summarization feature is useful, it has some limitations.
One limitation is that repeated requests to YouTube for transcripts may result in an IP block. YouTube can detect excessive requests and temporarily restrict access. To avoid this, it is advisable to introduce intervals between successive program runs or simply use the YouTube API.
Additionally, the quality of the summary depends on the quality of the transcript itself. If the transcript is inaccurate or lacks proper formatting, the generated summary may not be meaningful.
Conclusion
Despite its limitations, the summarization feature provides a quick and efficient way to condense YouTube transcripts. By ensuring high-quality transcripts, introducing intervals between runs, and handling punctuation properly, users can maximize the effectiveness of the summarization process. With these considerations, this tool remains a valuable asset for quickly extracting key insights from lengthy video transcripts. Check out our text summarization tutorial if you want to perform text summarization using transformers.
I hope you enjoyed this one. Till next time, Happy Coding!
Save time and energy with our Python Code Generator. Why start from scratch when you can generate? Give it a try!
View Full Code Convert My Code





Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!