Welcome! Meet our Python Code Assistant, your new coding buddy. Why wait? Start exploring now!
YouTube is no doubt the biggest video-sharing website on the Internet. It is one of the main sources of education, entertainment, advertisement, and many more fields. Since it's a data-rich website, accessing its API will enable you to get almost all of the YouTube data.
In this tutorial, we'll cover how to get YouTube video details and statistics, search by keyword, get YouTube channel information, and extract comments from both videos and channels, using YouTube API with Python.
Here is the table of contents:
- Enabling YouTube API
- Getting Video Details
- Searching by Keyword
- Getting YouTube Channel Details
- Extracting YouTube Comments
Enabling YouTube API
To enable YouTube Data API, you should follow below steps:
- Go to Google's API Console and create a project, or use an existing one.
- In the library panel, search for YouTube Data API v3, click on it and click Enable.
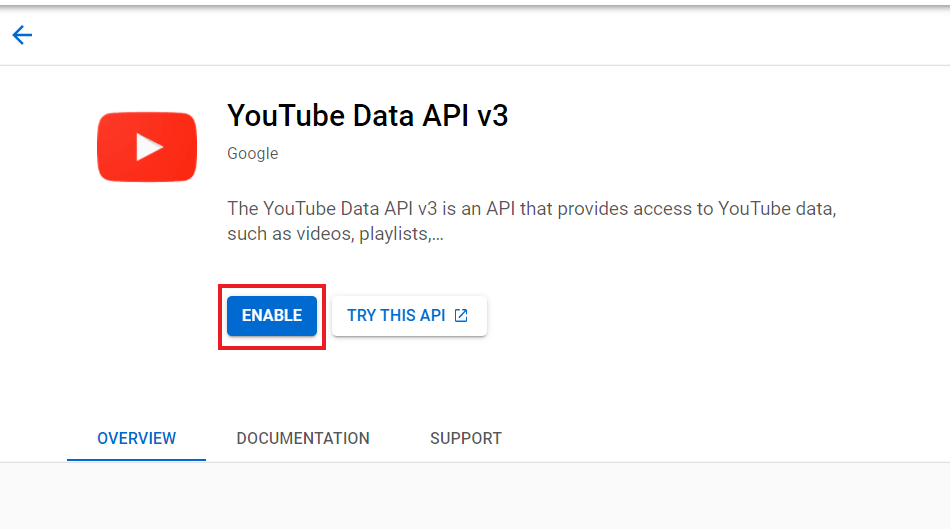
- In the credentials panel, click on Create Credentials, and choose OAuth client ID.
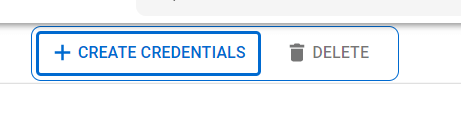
- Select Desktop App as the Application type and proceed.
- You'll see a window like this:
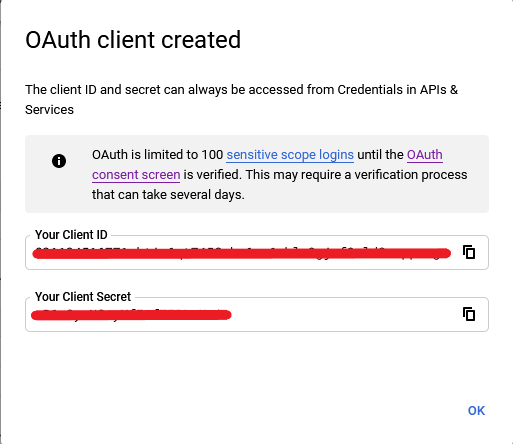
- Click OK and download the credentials file and rename it to
credentials.json:
Note: If this is the first time you use Google APIs, you may need to simply create an OAuth Consent screen and add your email as a testing user.
Now that you have set up YouTube API, get your credentials.json in the current directory of your notebook/Python file, and let's get started.
First, install required libraries:
$ pip3 install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlibNow let's import the necessary modules we gonna need:
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
import urllib.parse as p
import re
import os
import pickle
SCOPES = ["https://www.googleapis.com/auth/youtube.force-ssl"]SCOPES is a list of scopes of using YouTube API; we're using this one to view all YouTube data without any problems.
Now let's make the function that authenticates with YouTube API:
def youtube_authenticate():
os.environ["OAUTHLIB_INSECURE_TRANSPORT"] = "1"
api_service_name = "youtube"
api_version = "v3"
client_secrets_file = "credentials.json"
creds = None
# the file token.pickle stores the user's access and refresh tokens, and is
# created automatically when the authorization flow completes for the first time
if os.path.exists("token.pickle"):
with open("token.pickle", "rb") as token:
creds = pickle.load(token)
# if there are no (valid) credentials availablle, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(client_secrets_file, SCOPES)
creds = flow.run_local_server(port=0)
# save the credentials for the next run
with open("token.pickle", "wb") as token:
pickle.dump(creds, token)
return build(api_service_name, api_version, credentials=creds)
# authenticate to YouTube API
youtube = youtube_authenticate()youtube_authenticate() looks for the credentials.json file that we downloaded earlier, and try to authenticate using that file, this will open your default browser the first time you run it, so you accept the permissions. After that, it'll save a new file token.pickle that contains the authorized credentials.
It should look familiar if you used a Google API before, such as Gmail API, Google Drive API, or something else. The prompt in your default browser is to accept permissions required for the app. If you see a window that indicates the app isn't verified, you may just want to head to Advanced and click on your App name.
Getting Video Details
Now that you have everything set up, let's begin with extracting YouTube video details, such as title, description, upload time, and even statistics such as view count, and like count.
The following function will help us extract the video ID (that we'll need in the API) from a video URL:
def get_video_id_by_url(url):
"""
Return the Video ID from the video `url`
"""
# split URL parts
parsed_url = p.urlparse(url)
# get the video ID by parsing the query of the URL
video_id = p.parse_qs(parsed_url.query).get("v")
if video_id:
return video_id[0]
else:
raise Exception(f"Wasn't able to parse video URL: {url}")We simply used the urllib.parse module to get the video ID from a URL.
The below function gets a YouTube service object (returned from youtube_authenticate() function), as well as any keyword argument accepted by the API, and returns the API response for a specific video:
def get_video_details(youtube, **kwargs):
return youtube.videos().list(
part="snippet,contentDetails,statistics",
**kwargs
).execute()Notice we specified part of snippet, contentDetails and statistics, as these are the most important parts of the response in the API.
We also pass kwargs to the API directly. Next, let's define a function that takes a response returned from the above get_video_details() function, and prints the most useful information from a video:
def print_video_infos(video_response):
items = video_response.get("items")[0]
# get the snippet, statistics & content details from the video response
snippet = items["snippet"]
statistics = items["statistics"]
content_details = items["contentDetails"]
# get infos from the snippet
channel_title = snippet["channelTitle"]
title = snippet["title"]
description = snippet["description"]
publish_time = snippet["publishedAt"]
# get stats infos
comment_count = statistics["commentCount"]
like_count = statistics["likeCount"]
view_count = statistics["viewCount"]
# get duration from content details
duration = content_details["duration"]
# duration in the form of something like 'PT5H50M15S'
# parsing it to be something like '5:50:15'
parsed_duration = re.search(f"PT(\d+H)?(\d+M)?(\d+S)", duration).groups()
duration_str = ""
for d in parsed_duration:
if d:
duration_str += f"{d[:-1]}:"
duration_str = duration_str.strip(":")
print(f"""\
Title: {title}
Description: {description}
Channel Title: {channel_title}
Publish time: {publish_time}
Duration: {duration_str}
Number of comments: {comment_count}
Number of likes: {like_count}
Number of views: {view_count}
""")Finally, let's use these functions to extract information from a demo video:
video_url = "https://www.youtube.com/watch?v=jNQXAC9IVRw&ab_channel=jawed"
# parse video ID from URL
video_id = get_video_id_by_url(video_url)
# make API call to get video info
response = get_video_details(youtube, id=video_id)
# print extracted video infos
print_video_infos(response)We first get the video ID from the URL, and then we get the response from the API call and finally print the data. Here is the output:
Title: Me at the zoo
Description: The first video on YouTube. Maybe it's time to go back to the zoo?
Channel Title: jawed
Publish time: 2005-04-24T03:31:52Z
Duration: 19
Number of comments: 11018071
Number of likes: 5962957
Number of views: 138108884You see, we used the id parameter to get the details of a specific video, you can also set multiple video IDs separated by commas, so you make a single API call to get details about multiple videos, check the documentation for more detailed information.
Searching By Keyword
Searching using YouTube API is straightforward; we simply pass q parameter for query, the same query we use in the YouTube search bar:
def search(youtube, **kwargs):
return youtube.search().list(
part="snippet",
**kwargs
).execute()This time we care about the snippet, and we use search() instead of videos() like in the previously defined get_video_details() function.
Let's, for example, search for "python" and limit the results to only 2:
# search for the query 'python' and retrieve 2 items only
response = search(youtube, q="python", maxResults=2)
items = response.get("items")
for item in items:
# get the video ID
video_id = item["id"]["videoId"]
# get the video details
video_response = get_video_details(youtube, id=video_id)
# print the video details
print_video_infos(video_response)
print("="*50)We set maxResults to 2 so we retrieve the first two items, here is a part of the output:
Title: Learn Python - Full Course for Beginners [Tutorial]
Description: This course will give you a full introduction into all of the core concepts in python...<SNIPPED>
Channel Title: freeCodeCamp.org
Publish time: 2018-07-11T18:00:42Z
Duration: 4:26:52
Number of comments: 30307
Number of likes: 520260
Number of views: 21032973
==================================================
Title: Python Tutorial - Python for Beginners [Full Course]
Description: Python tutorial - Python for beginners
Learn Python programming for a career in machine learning, data science & web development...<SNIPPED>
Channel Title: Programming with Mosh
Publish time: 2019-02-18T15:00:08Z
Duration: 6:14:7
Number of comments: 38019
Number of likes: 479749
Number of views: 15575418You can also specify the order parameter in search() function to order search results, which can be 'date', 'rating', 'viewCount', 'relevance' (default), 'title', and 'videoCount'.
Another useful parameter is the type, which can be 'channel', 'playlist' or 'video', default is all of them.
Please check this page for more information about the search().list() method.
Getting YouTube Channel Details
This section will take a channel URL and extract channel information using YouTube API.
First, we need helper functions to parse the channel URL. The below functions will help us to do that:
def parse_channel_url(url):
"""
This function takes channel `url` to check whether it includes a
channel ID, user ID or channel name
"""
path = p.urlparse(url).path
id = path.split("/")[-1]
if "/c/" in path:
return "c", id
elif "/channel/" in path:
return "channel", id
elif "/user/" in path:
return "user", id
def get_channel_id_by_url(youtube, url):
"""
Returns channel ID of a given `id` and `method`
- `method` (str): can be 'c', 'channel', 'user'
- `id` (str): if method is 'c', then `id` is display name
if method is 'channel', then it's channel id
if method is 'user', then it's username
"""
# parse the channel URL
method, id = parse_channel_url(url)
if method == "channel":
# if it's a channel ID, then just return it
return id
elif method == "user":
# if it's a user ID, make a request to get the channel ID
response = get_channel_details(youtube, forUsername=id)
items = response.get("items")
if items:
channel_id = items[0].get("id")
return channel_id
elif method == "c":
# if it's a channel name, search for the channel using the name
# may be inaccurate
response = search(youtube, q=id, maxResults=1)
items = response.get("items")
if items:
channel_id = items[0]["snippet"]["channelId"]
return channel_id
raise Exception(f"Cannot find ID:{id} with {method} method")Now we can parse the channel URL. Let's define our functions to call the YouTube API:
def get_channel_videos(youtube, **kwargs):
return youtube.search().list(
**kwargs
).execute()
def get_channel_details(youtube, **kwargs):
return youtube.channels().list(
part="statistics,snippet,contentDetails",
**kwargs
).execute()We'll be using get_channel_videos() to get the videos of a specific channel, and get_channel_details() will allow us to extract information about a specific youtube channel.
Now that we have everything, let's make a concrete example:
channel_url = "https://www.youtube.com/channel/UC8butISFwT-Wl7EV0hUK0BQ"
# get the channel ID from the URL
channel_id = get_channel_id_by_url(youtube, channel_url)
# get the channel details
response = get_channel_details(youtube, id=channel_id)
# extract channel infos
snippet = response["items"][0]["snippet"]
statistics = response["items"][0]["statistics"]
channel_country = snippet["country"]
channel_description = snippet["description"]
channel_creation_date = snippet["publishedAt"]
channel_title = snippet["title"]
channel_subscriber_count = statistics["subscriberCount"]
channel_video_count = statistics["videoCount"]
channel_view_count = statistics["viewCount"]
print(f"""
Title: {channel_title}
Published At: {channel_creation_date}
Description: {channel_description}
Country: {channel_country}
Number of videos: {channel_video_count}
Number of subscribers: {channel_subscriber_count}
Total views: {channel_view_count}
""")
# the following is grabbing channel videos
# number of pages you want to get
n_pages = 2
# counting number of videos grabbed
n_videos = 0
next_page_token = None
for i in range(n_pages):
params = {
'part': 'snippet',
'q': '',
'channelId': channel_id,
'type': 'video',
}
if next_page_token:
params['pageToken'] = next_page_token
res = get_channel_videos(youtube, **params)
channel_videos = res.get("items")
for video in channel_videos:
n_videos += 1
video_id = video["id"]["videoId"]
# easily construct video URL by its ID
video_url = f"https://www.youtube.com/watch?v={video_id}"
video_response = get_video_details(youtube, id=video_id)
print(f"================Video #{n_videos}================")
# print the video details
print_video_infos(video_response)
print(f"Video URL: {video_url}")
print("="*40)
print("*"*100)
# if there is a next page, then add it to our parameters
# to proceed to the next page
if "nextPageToken" in res:
next_page_token = res["nextPageToken"]We first get the channel ID from the URL, and then we make an API call to get channel details and print them.
After that, we specify the number of pages of videos we want to extract. The default is ten videos per page, and we can also change that by passing the maxResults parameter.
We iterate on each video and make an API call to get various information about the video, and we use our predefined print_video_infos() to print the video information.
Here is a part of the output:
================Video #1================
Title: Async + Await in JavaScript, talk from Wes Bos
Description: Flow Control in JavaScript is hard! ...
Channel Title: freeCodeCamp.org
Publish time: 2018-04-16T16:58:08Z
Duration: 15:52
Number of comments: 52
Number of likes: 2353
Number of views: 74562
Video URL: https://www.youtube.com/watch?v=DwQJ_NPQWWo
========================================
================Video #2================
Title: Protected Routes in React using React Router
Description: In this video, we will create a protected route using...
Channel Title: freeCodeCamp.org
Publish time: 2018-10-16T16:00:05Z
Duration: 15:40
Number of comments: 158
Number of likes: 3331
Number of views: 173927
Video URL: https://www.youtube.com/watch?v=Y0-qdp-XBJg
...<SNIPPED>You can get other information; you can print the response dictionary for further information or check the documentation for this endpoint.
Extracting YouTube Comments
YouTube API allows us to extract comments; this is useful if you want to get comments for your text classification project or something similar.
The below function takes care of making an API call to commentThreads():
def get_comments(youtube, **kwargs):
return youtube.commentThreads().list(
part="snippet",
**kwargs
).execute()The below code extracts comments from a YouTube video:
# URL can be a channel or a video, to extract comments
url = "https://www.youtube.com/watch?v=jNQXAC9IVRw&ab_channel=jawed"
if "watch" in url:
# that's a video
video_id = get_video_id_by_url(url)
params = {
'videoId': video_id,
'maxResults': 2,
'order': 'relevance', # default is 'time' (newest)
}
else:
# should be a channel
channel_id = get_channel_id_by_url(url)
params = {
'allThreadsRelatedToChannelId': channel_id,
'maxResults': 2,
'order': 'relevance', # default is 'time' (newest)
}
# get the first 2 pages (2 API requests)
n_pages = 2
for i in range(n_pages):
# make API call to get all comments from the channel (including posts & videos)
response = get_comments(youtube, **params)
items = response.get("items")
# if items is empty, breakout of the loop
if not items:
break
for item in items:
comment = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
updated_at = item["snippet"]["topLevelComment"]["snippet"]["updatedAt"]
like_count = item["snippet"]["topLevelComment"]["snippet"]["likeCount"]
comment_id = item["snippet"]["topLevelComment"]["id"]
print(f"""\
Comment: {comment}
Likes: {like_count}
Updated At: {updated_at}
==================================\
""")
if "nextPageToken" in response:
# if there is a next page
# add next page token to the params we pass to the function
params["pageToken"] = response["nextPageToken"]
else:
# must be end of comments!!!!
break
print("*"*70)You can also change url variable to be a YouTube channel URL so that it will pass allThreadsRelatedToChannelId instead of videoId as a parameter to commentThreads() API.
We're extracting two comments per page and two pages, so four comments in total. Here is the output:
Comment: We're so honored that the first ever YouTube video was filmed here!
Likes: 877965
Updated At: 2020-02-17T18:58:15Z
==================================
Comment: Wow, still in your recommended in 2021? Nice! Yay
Likes: 10951
Updated At: 2021-01-04T15:32:38Z
==================================
**********************************************************************
Comment: How many are seeing this video now
Likes: 7134
Updated At: 2021-01-03T19:47:25Z
==================================
Comment: The first youtube video EVER. Wow.
Likes: 865
Updated At: 2021-01-05T00:55:35Z
==================================
**********************************************************************We're extracting the comment itself, the number of likes, and the last updated date; you can explore the response dictionary to get various other useful information.
You're free to edit the parameters we passed, such as increasing the maxResults, or changing the order. Please check the page for this API endpoint.
Conclusion
YouTube Data API provides a lot more than what we covered here. If you have a YouTube channel, you can upload, update and delete videos, and much more.
I invite you to explore more in the YouTube API documentation for advanced search techniques, getting playlist details, members, and much more.
If you want to extract YouTube data but don't want to use the API, then we also have a tutorial on getting YouTube data with web scraping (more like an unofficial way to do it).
Below are some of the Google API tutorials:
- How to Extract Google Trends Data in Python.
- How to Use Google Drive API in Python.
- How to Use Gmail API in Python.
- How to Use Google Custom Search Engine API in Python.
Happy Coding ♥
Liked what you read? You'll love what you can learn from our AI-powered Code Explainer. Check it out!
View Full Code Generate Python Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!