Get a head start on your coding projects with our Python Code Generator. Perfect for those times when you need a quick solution. Don't wait, try it today!
Web scraping is extracting data from websites. It is a form of copying in which specific data is gathered and copied from the web into a central local database or spreadsheet for later analysis or retrieval.
Since YouTube is the biggest video-sharing website on the internet, extracting data can be very helpful. You can find the most popular channels, keep track of the popularity of channels, record likes and views on videos, and much more. This tutorial will show how to extract data from YouTube videos using requests_html and BeautifulSoup in Python.
Note that it isn't reliable to use this method to extract YouTube data, as YouTube keeps changing its code. The code of this tutorial can fail at any time. Therefore, for more reliable use, I suggest you use YouTube API for extracting data instead.
Related: How to Extract YouTube Comments in Python.
Installing required dependencies:
pip3 install requests_html bs4Before we dive into the quick script, we are going to need to experiment on how to extract such data from websites using BeautifulSoup, open up a Python interactive shell and write these lines of code:
from requests_html import HTMLSession
from bs4 import BeautifulSoup as bs # importing BeautifulSoup
# sample youtube video url
video_url = "https://www.youtube.com/watch?v=jNQXAC9IVRw"
# init an HTML Session
session = HTMLSession()
# get the html content
response = session.get(video_url)
# execute Java-script
response.html.render(sleep=1)
# create bs object to parse HTML
soup = bs(response.html.html, "html.parser")The above code requests that YouTube video URL, renders the Javascript, and finally creates the BeatifulSoup object wrapping the resulting HTML.
Great, now let's try to find all meta tags on the page:
In [10]: soup.find_all("meta")
Out[10]:
[<meta content="IE=edge" http-equiv="X-UA-Compatible"/>,
<meta content="rgba(255,255,255,0.98)" name="theme-color"/>,
<meta content="Me at the zoo" name="title"/>,
<meta content="The first video on YouTube. While you wait for Part 2, listen to this great song: https://www.youtube.com/watch?v=zj82_v2R6ts" name="description"/>,
<meta content="me at the zoo, jawed karim, first youtube video" name="keywords"/>,
<meta content="YouTube" property="og:site_name"/>,
<meta content="https://www.youtube.com/watch?v=jNQXAC9IVRw" property="og:url"/>,
<meta content="Me at the zoo" property="og:title"/>,
<meta content="https://i.ytimg.com/vi/jNQXAC9IVRw/hqdefault.jpg" property="og:image"/>,
<meta content="480" property="og:image:width"/>,
<meta content="360" property="og:image:height"/>,
<meta content="The first video on YouTube. While you wait for Part 2, listen to this great song: https://www.youtube.com/watch?v=zj82_v2R6ts" property="og:description"/>,
<meta content="544007664" property="al:ios:app_store_id"/>,
<meta content="YouTube" property="al:ios:app_name"/>,
<meta content="vnd.youtube://www.youtube.com/watch?v=jNQXAC9IVRw&feature=applinks" property="al:ios:url"/>,
<meta content="vnd.youtube://www.youtube.com/watch?v=jNQXAC9IVRw&feature=applinks" property="al:android:url"/>,
<meta content="http://www.youtube.com/watch?v=jNQXAC9IVRw&feature=applinks" property="al:web:url"/>,
<meta content="video.other" property="og:type"/>,
<meta content="https://www.youtube.com/embed/jNQXAC9IVRw" property="og:video:url"/>,
<meta content="https://www.youtube.com/embed/jNQXAC9IVRw" property="og:video:secure_url"/>,
<meta content="text/html" property="og:video:type"/>,
<meta content="480" property="og:video:width"/>,
<meta content="360" property="og:video:height"/>,
<meta content="YouTube" property="al:android:app_name"/>,
<meta content="com.google.android.youtube" property="al:android:package"/>,
<meta content="me at the zoo" property="og:video:tag"/>,
<meta content="jawed karim" property="og:video:tag"/>,
<meta content="first youtube video" property="og:video:tag"/>,
<meta content="87741124305" property="fb:app_id"/>,
<meta content="player" name="twitter:card"/>,
<meta content="@youtube" name="twitter:site"/>,
<meta content="https://www.youtube.com/watch?v=jNQXAC9IVRw" name="twitter:url"/>,
<meta content="Me at the zoo" name="twitter:title"/>,
<meta content="The first video on YouTube. While you wait for Part 2, listen to this great song: https://www.youtube.com/watch?v=zj82_v2R6ts" name="twitter:description"/>,
<meta content="https://i.ytimg.com/vi/jNQXAC9IVRw/hqdefault.jpg" name="twitter:image"/>,
<meta content="YouTube" name="twitter:app:name:iphone"/>,
<meta content="544007664" name="twitter:app:id:iphone"/>,
<meta content="YouTube" name="twitter:app:name:ipad"/>,
<meta content="544007664" name="twitter:app:id:ipad"/>,
<meta content="vnd.youtube://www.youtube.com/watch?v=jNQXAC9IVRw&feature=applinks" name="twitter:app:url:iphone"/>,
<meta content="vnd.youtube://www.youtube.com/watch?v=jNQXAC9IVRw&feature=applinks" name="twitter:app:url:ipad"/>,
<meta content="YouTube" name="twitter:app:name:googleplay"/>,
<meta content="com.google.android.youtube" name="twitter:app:id:googleplay"/>,
<meta content="https://www.youtube.com/watch?v=jNQXAC9IVRw" name="twitter:app:url:googleplay"/>,
<meta content="https://www.youtube.com/embed/jNQXAC9IVRw" name="twitter:player"/>,
<meta content="480" name="twitter:player:width"/>,
<meta content="360" name="twitter:player:height"/>,
<meta content="Me at the zoo" itemprop="name"/>,
<meta content="The first video on YouTube. While you wait for Part 2, listen to this great song: https://www.youtube.com/watch?v=zj82_v2R6ts" itemprop="description"/>,
<meta content="False" itemprop="paid"/>,
<meta content="UC4QobU6STFB0P71PMvOGN5A" itemprop="channelId"/>,
<meta content="jNQXAC9IVRw" itemprop="videoId"/>,
<meta content="PT0M19S" itemprop="duration"/>,
<meta content="False" itemprop="unlisted"/>,
<meta content="480" itemprop="width"/>,
<meta content="360" itemprop="height"/>,
<meta content="HTML5 Flash" itemprop="playerType"/>,
<meta content="480" itemprop="width"/>,
<meta content="360" itemprop="height"/>,
<meta content="true" itemprop="isFamilyFriendly"/>,
<meta content="AD,AE,AF,AG,AI,AL,AM,AO,AQ,AR,AS,AT,AU,AW,AX,AZ,BA,BB,BD,BE,BF,BG,BH,BI,BJ,BL,BM,BN,BO,BQ,BR,BS,BT,BV,BW,BY,BZ,CA,CC,CD,CF,CG,CH,CI,CK,CL,CM,CN,CO,CR,CU,CV,CW,CX,CY,CZ,DE,DJ,DK,DM,DO,DZ,EC,EE,EG,EH,ER,ES,ET,FI,FJ,FK,FM,FO,FR,GA,GB,GD,GE,GF,GG,GH,GI,GL,GM,GN,GP,GQ,GR,GS,GT,GU,GW,GY,HK,HM,HN,HR,HT,HU,ID,IE,IL,IM,IN,IO,IQ,IR,IS,IT,JE,JM,JO,JP,KE,KG,KH,KI,KM,KN,KP,KR,KW,KY,KZ,LA,LB,LC,LI,LK,LR,LS,LT,LU,LV,LY,MA,MC,MD,ME,MF,MG,MH,MK,ML,MM,MN,MO,MP,MQ,MR,MS,MT,MU,MV,MW,MX,MY,MZ,NA,NC,NE,NF,NG,NI,NL,NO,NP,NR,NU,NZ,OM,PA,PE,PF,PG,PH,PK,PL,PM,PN,PR,PS,PT,PW,PY,QA,RE,RO,RS,RU,RW,SA,SB,SC,SD,SE,SG,SH,SI,SJ,SK,SL,SM,SN,SO,SR,SS,ST,SV,SX,SY,SZ,TC,TD,TF,TG,TH,TJ,TK,TL,TM,TN,TO,TR,TT,TV,TW,TZ,UA,UG,UM,US,UY,UZ,VA,VC,VE,VG,VI,VN,VU,WF,WS,YE,YT,ZA,ZM,ZW" itemprop="regionsAllowed"/>,
<meta content="172826227" itemprop="interactionCount"/>,
<meta content="2005-04-23" itemprop="datePublished"/>,
<meta content="2005-04-23" itemprop="uploadDate"/>,
<meta content="Film & Animation" itemprop="genre"/>]Easy as that, a lot of valuable data here. For example, we can get the video title by:
In [11]: soup.find("meta", itemprop="name")["content"]
Out[11]: 'Me at the zoo'Or the number of views:
In [12]: soup.find("meta", itemprop="interactionCount")['content']
Out[12]: '172826227'This way, you will be able to extract everything you want from that web page. Now let's make our script that extracts some useful information we can get from a YouTube video page, open up a new Python file and follow along:
Importing necessary modules:
from requests_html import HTMLSession
from bs4 import BeautifulSoup as bsBefore we make our function that extract all video data, let's initialize our HTTP session:
# init session
session = HTMLSession()Let's make a function; given a URL of a YouTube video, it will return all the data in a dictionary:
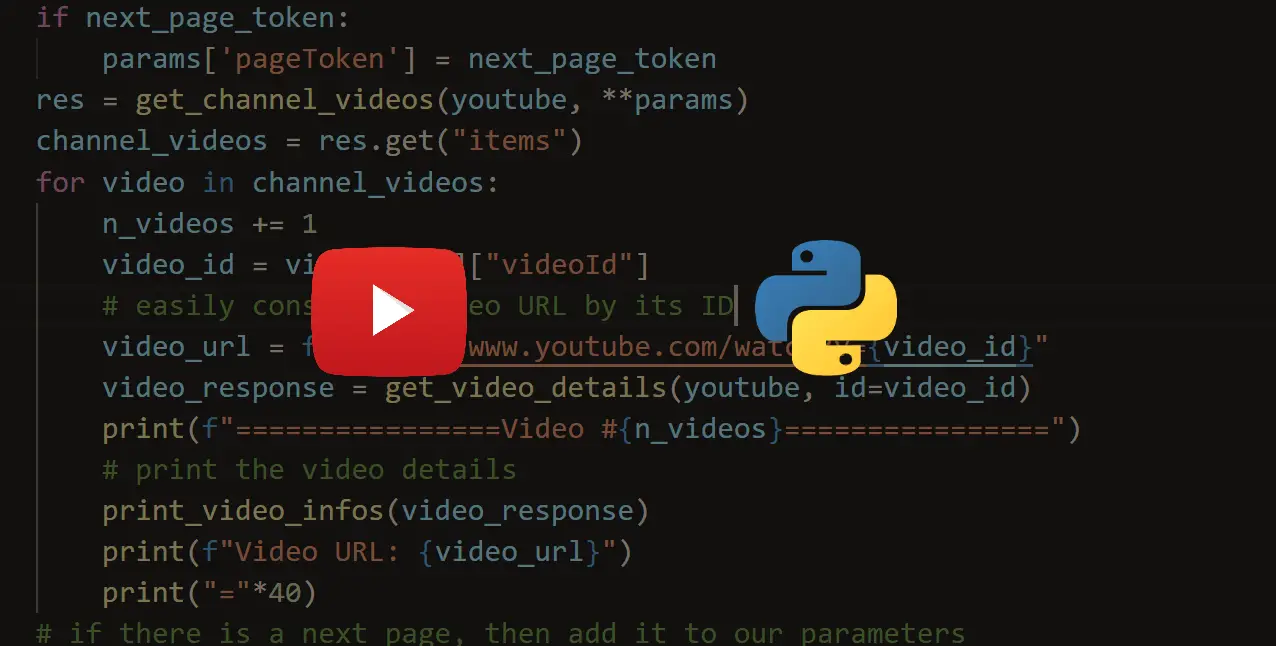
def get_video_info(url):
# download HTML code
response = session.get(url)
# execute Javascript
response.html.render(sleep=1)
# create beautiful soup object to parse HTML
soup = bs(response.html.html, "html.parser")
# open("index.html", "w").write(response.html.html)
# initialize the result
result = {}Notice after we downloaded the HTML content of the web page, we ran render() method to execute Javascript so that the data we're looking for is rendered in the HTML.
Note that if you get a timeout error, then you can simply add timeout parameter and set it to 60 seconds (default is 8 seconds) or something, like so:
response.html.render(sleep=1, timeout=60)Retrieving the video title:
# video title
result["title"] = soup.find("meta", itemprop="name")['content']The number of views converted to an integer:
# video views (converted to integer)
result["views"] = result["views"] = soup.find("meta", itemprop="interactionCount")['content']Get the video description:
# video description
result["description"] = soup.find("meta", itemprop="description")['content']The date when the video was published:
# date published
result["date_published"] = soup.find("meta", itemprop="datePublished")['content']The duration of the video:
# get the duration of the video
result["duration"] = soup.find("span", {"class": "ytp-time-duration"}).textWe could get the duration from the meta tag as previous fields, but it'll be in another format, such as PT0M19S which translates to 19 seconds or 00:19 in the format that is in the ytp-time-duration span tag.
We can also extract the video tags:
# get the video tags
result["tags"] = ', '.join([ meta.attrs.get("content") for meta in soup.find_all("meta", {"property": "og:video:tag"}) ])The number of likes:
# Additional video and channel information (with help from: https://stackoverflow.com/a/68262735)
data = re.search(r"var ytInitialData = ({.*?});", soup.prettify()).group(1)
data_json = json.loads(data)
videoPrimaryInfoRenderer = data_json['contents']['twoColumnWatchNextResults']['results']['results']['contents'][0]['videoPrimaryInfoRenderer']
videoSecondaryInfoRenderer = data_json['contents']['twoColumnWatchNextResults']['results']['results']['contents'][1]['videoSecondaryInfoRenderer']
# number of likes
likes_label = videoPrimaryInfoRenderer['videoActions']['menuRenderer']['topLevelButtons'][0]['toggleButtonRenderer']['defaultText']['accessibility']['accessibilityData']['label'] # "No likes" or "###,### likes"
likes_str = likes_label.split(' ')[0].replace(',','')
result["likes"] = '0' if likes_str == 'No' else likes_str
# number of likes (old way) doesn't always work
# text_yt_formatted_strings = soup.find_all("yt-formatted-string", {"id": "text", "class": "ytd-toggle-button-renderer"})
# result["likes"] = ''.join([ c for c in text_yt_formatted_strings[0].attrs.get("aria-label") if c.isdigit() ])
# result["likes"] = 0 if result['likes'] == '' else int(result['likes'])
# number of dislikes - YouTube does not publish this anymore...
# result["dislikes"] = ''.join([ c for c in text_yt_formatted_strings[1].attrs.get("aria-label") if c.isdigit() ])
# result["dislikes"] = '0' if result['dislikes'] == '' else result['dislikes']
result['dislikes'] = 'UNKNOWN'As you may notice, there are two different ways. The commented way seems inconsistent and sometimes crashes after YouTube updates. Therefore, the newer method appears to cope with the updates (thanks to Matt for the contribution). Also, the dislikes are no longer shown publicly in YouTube videos; they're commented for now.
Since in a YouTube video, you can see the channel details, such as the name, and the number of subscribers, let's grab that as well:
# channel details
channel_tag = soup.find("meta", itemprop="channelId")['content']
# channel name
channel_name = soup.find("span", itemprop="author").next.next['content']
# channel URL
# channel_url = soup.find("span", itemprop="author").next['href']
channel_url = f"https://www.youtube.com/{channel_tag}"
# number of subscribers as str
channel_subscribers = videoSecondaryInfoRenderer['owner']['videoOwnerRenderer']['subscriberCountText']['accessibility']['accessibilityData']['label']
# channel details (old way)
# channel_tag = soup.find("yt-formatted-string", {"class": "ytd-channel-name"}).find("a")
# # channel name (old way)
# channel_name = channel_tag.text
# # channel URL (old way)
# channel_url = f"https://www.youtube.com{channel_tag['href']}"
# number of subscribers as str (old way)
# channel_subscribers = soup.find("yt-formatted-string", {"id": "owner-sub-count"}).text.strip()
result['channel'] = {'name': channel_name, 'url': channel_url, 'subscribers': channel_subscribers}
return resultSince soup.find() function returns a Tag object. You can still find HTML tags within other tags. As a result, It is common to call find() more than once.
Now, this function returns a lot of video information in a dictionary. Let's finish up our script:
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="YouTube Video Data Extractor")
parser.add_argument("url", help="URL of the YouTube video")
args = parser.parse_args()
url = args.url
# get the data
data = get_video_info(url)
# print in nice format
print(f"Title: {data['title']}")
print(f"Views: {data['views']}")
print(f"Published at: {data['date_published']}")
print(f"Video Duration: {data['duration']}")
print(f"Video tags: {data['tags']}")
print(f"Likes: {data['likes']}")
print(f"Dislikes: {data['dislikes']}")
print(f"\nDescription: {data['description']}\n")
print(f"\nChannel Name: {data['channel']['name']}")
print(f"Channel URL: {data['channel']['url']}")
print(f"Channel Subscribers: {data['channel']['subscribers']}")There is nothing special here since we need a way to retrieve the video URL from the command line. The above does just that and then prints it in a format. Here is my output when running the script:
C:\youtube-extractor>python extract_video_info.py https://www.youtube.com/watch?v=jNQXAC9IVRw
Title: Me at the zoo
Views: 172639597
Published at: 2005-04-23
Video Duration: 0:18
Video tags: me at the zoo, jawed karim, first youtube video
Likes: 8188077
Dislikes: 191986
Description: The first video on YouTube. While you wait for Part 2, listen to this great song: https://www.youtube.com/watch?v=zj82_v2R6ts
Channel Name: jawed
Channel URL: https://www.youtube.com/channel/UC4QobU6STFB0P71PMvOGN5A
Channel Subscribers: 1.98M subscribersConclusion
That is it! You know how to extract data from HTML tags, then go on and add other fields such as video quality and others.
If you want to extract YouTube comments, there are many things to do besides this. There is a separate tutorial for this.
You can not only extract YouTube video details, but you can also apply this skill to any website you want. If you're going to extract Wikipedia pages, there is a tutorial for that! Or maybe you want to scrape weather data from Google? There is a tutorial for that as well.
Check the complete code of this tutorial here.
Note: YouTube constantly changes the HTML structure of video pages. If the code of this tutorial doesn't work for you, please check out using the YouTube API tutorial instead.
Want to Learn More about Web Scraping?
Finally, if you want to dig more into web scraping with different Python libraries, not just BeautifulSoup, the below courses will be valuable for you:
- Modern Web Scraping with Python using Scrapy Splash Selenium.
- Web Scraping and API Fundamentals in Python 2021.
Learn also: How to Convert HTML Tables into CSV Files in Python.
Happy Scraping ♥
Liked what you read? You'll love what you can learn from our AI-powered Code Explainer. Check it out!
View Full Code Fix My Code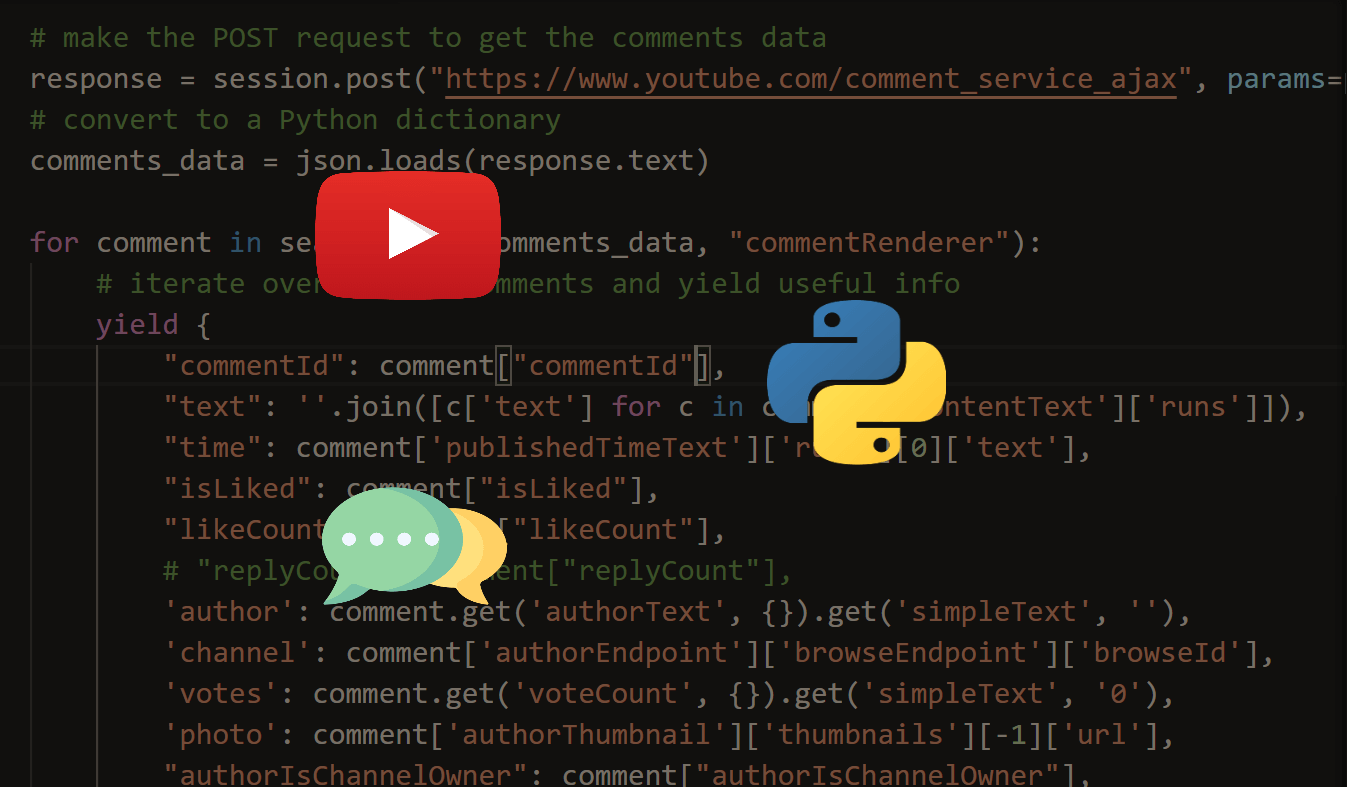



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!