Confused by complex code? Let our AI-powered Code Explainer demystify it for you. Try it out!
As you may know, Web scraping is essentially extracting data from websites. Doing such a task in a high-level programming language like Python is very handy and powerful. In this tutorial, you will learn how to use requests and BeautifulSoup to scrape weather data from the Google search engine.
Although, this is not the perfect and official way to get the actual weather for a specific location, because there are hundreds of weather APIs out there to use. However, it is a great exercise for you to get familiar with scraping.
There are also handy tools that are already built with Python, such as wttr.in.
Related: How to Make an Email Extractor in Python.
Alright, let's get started, installing the required dependencies:
pip3 install requests bs4First, let's experiment a little bit, open up a Google search bar and type for instance: "weather london", you'll see the official weather, let's right-click and inspect HTML code as shown in the following figure:
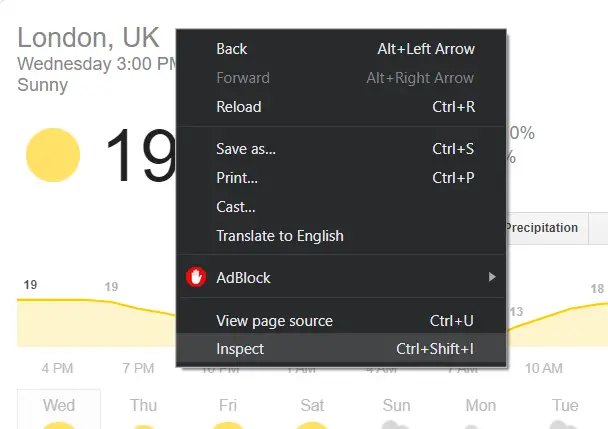
Note: Google does not have its appropriate weather API, as it also scrapes weather data from weather.com, so we are essentially scraping from it.
You'll be forwarded to HTML code that is responsible for displaying the region, day and hour, and the actual weather:
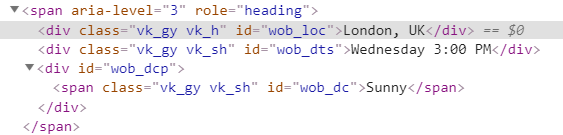
Great, let's try to extract this information in a Python interactive shell quickly:
In [7]: soup = BeautifulSoup(requests.get("https://www.google.com/search?q=weather+london").content)
In [8]: soup.find("div", attrs={'id': 'wob_loc'}).text
Out[8]: 'London, UK'Don't worry about how we created the soup object, all you need to worry about right now is how you can grab that information from HTML code, all you have to specify to soup.find() method is the HTML tag name and the matched attributes, in this case, a div element with an id of "wob_loc" will get us the location.
Similarly, let's extract the current day and time:
In [9]: soup.find("div", attrs={"id": "wob_dts"}).text
Out[9]: 'Wednesday 3:00 PM'The actual weather:
In [10]: soup.find("span", attrs={"id": "wob_dc"}).text
Out[10]: 'Sunny'Alright, now you are familiar with it, let's create our quick script for grabbing more information about the weather (as much information as we can). Open up a new Python script and follow with me.
First, let's import the necessary modules:
from bs4 import BeautifulSoup as bs
import requestsIt is worth noting that Google tries to prevent us to scrape its website programmatically, as it is an unofficial way to get data because it provides us with a convenient alternative, which is the Custom Search Engine (check this tutorial for how to use it), but just for educational purposes, we gonna pretend that we are a legitimate web browser, let's define the user-agent:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
# US english
LANGUAGE = "en-US,en;q=0.5"This link provides you with the latest browser versions, make sure you replace USER_AGENT with the newest.
Let's define a function that given a URL, it tries to extract all useful weather information and return it in a dictionary:
def get_weather_data(url):
session = requests.Session()
session.headers['User-Agent'] = USER_AGENT
session.headers['Accept-Language'] = LANGUAGE
session.headers['Content-Language'] = LANGUAGE
html = session.get(url)
# create a new soup
soup = bs(html.text, "html.parser")All we did here, is to create a session with that browser and language, and then download the HTML code using session.get(url) from the web, and finally creating the BeautifulSoup object with an HTML parser.
Let's get current region, weather, temperature, and actual day and hour:
# store all results on this dictionary
result = {}
# extract region
result['region'] = soup.find("div", attrs={"id": "wob_loc"}).text
# extract temperature now
result['temp_now'] = soup.find("span", attrs={"id": "wob_tm"}).text
# get the day and hour now
result['dayhour'] = soup.find("div", attrs={"id": "wob_dts"}).text
# get the actual weather
result['weather_now'] = soup.find("span", attrs={"id": "wob_dc"}).textSince the current precipitation, humidity and wind are displayed, why not grab them?
# get the precipitation
result['precipitation'] = soup.find("span", attrs={"id": "wob_pp"}).text
# get the % of humidity
result['humidity'] = soup.find("span", attrs={"id": "wob_hm"}).text
# extract the wind
result['wind'] = soup.find("span", attrs={"id": "wob_ws"}).textLet's try to get weather information about the next few days, if you take some time finding the HTML code of it, you'll find something similar to this:
<div class="wob_df"
style="display:inline-block;line-height:1;text-align:center;-webkit-transition-duration:200ms,200ms,200ms;-webkit-transition-property:background-image,border,font-weight;font-weight:13px;height:90px;width:73px"
data-wob-di="3" role="button" tabindex="0" data-ved="2ahUKEwifm-6c6NrkAhUBdBQKHVbBADoQi2soAzAAegQIDBAN">
<div class="Z1VzSb" aria-label="Saturday">Sat</div>
<div style="display:inline-block"><img style="margin:1px 4px 0;height:48px;width:48px" alt="Sunny"
src="//ssl.gstatic.com/onebox/weather/48/sunny.png" data-atf="1"></div>
<div style="font-weight:normal;line-height:15px;font-size:13px">
<div class="vk_gy" style="display:inline-block;padding-right:5px"><span class="wob_t"
style="display:inline">25</span><span class="wob_t" style="display:none">77</span>°</div>
<div class="vk_lgy" style="display:inline-block"><span class="wob_t" style="display:inline">17</span><span
class="wob_t" style="display:none">63</span>°</div>
</div>
</div>Not human-readable, I know, but this parent div contains all information about one next day, which is "Saturday" as shown in the first child div element with the class of Z1VzSb in the aria-label attribute, the weather information is within the alt attribute in the img element, in this case, "Sunny". The temperature, however, there is max and min with both Celsius and Fahrenheit, these lines of code takes care of everything:
# get next few days' weather
next_days = []
days = soup.find("div", attrs={"id": "wob_dp"})
for day in days.findAll("div", attrs={"class": "wob_df"}):
# extract the name of the day
day_name = day.findAll("div")[0].attrs['aria-label']
# get weather status for that day
weather = day.find("img").attrs["alt"]
temp = day.findAll("span", {"class": "wob_t"})
# maximum temparature in Celsius, use temp[1].text if you want fahrenheit
max_temp = temp[0].text
# minimum temparature in Celsius, use temp[3].text if you want fahrenheit
min_temp = temp[2].text
next_days.append({"name": day_name, "weather": weather, "max_temp": max_temp, "min_temp": min_temp})
# append to result
result['next_days'] = next_days
return resultNow result dictionary got everything we need, let's finish up the script by parsing command-line arguments using argparse:
if __name__ == "__main__":
URL = "https://www.google.com/search?lr=lang_en&ie=UTF-8&q=weather"
import argparse
parser = argparse.ArgumentParser(description="Quick Script for Extracting Weather data using Google Weather")
parser.add_argument("region", nargs="?", help="""Region to get weather for, must be available region.
Default is your current location determined by your IP Address""", default="")
# parse arguments
args = parser.parse_args()
region = args.region
URL += region
# get data
data = get_weather_data(URL)Displaying everything:
# print data
print("Weather for:", data["region"])
print("Now:", data["dayhour"])
print(f"Temperature now: {data['temp_now']}°C")
print("Description:", data['weather_now'])
print("Precipitation:", data["precipitation"])
print("Humidity:", data["humidity"])
print("Wind:", data["wind"])
print("Next days:")
for dayweather in data["next_days"]:
print("="*40, dayweather["name"], "="*40)
print("Description:", dayweather["weather"])
print(f"Max temperature: {dayweather['max_temp']}°C")
print(f"Min temperature: {dayweather['min_temp']}°C")If you run this script, it will automatically grab the weather of your current region determined by your IP address. However, if you want a different region, you can pass it as arguments:
C:\weather-extractor>python weather.py "New York"This will show weather data of New York state in the US:
Weather for: New York, NY, USA
Now: wednesday 2:00 PM
Temperature now: 20°C
Description: Mostly Cloudy
Precipitation: 0%
Humidity: 52%
Wind: 13 km/h
Next days:
======================================== wednesday ========================================
Description: Mostly Cloudy
Max temperature: 21°C
Min temperature: 12°C
======================================== thursday ========================================
Description: Sunny
Max temperature: 22°C
Min temperature: 14°C
======================================== friday ========================================
Description: Partly Sunny
Max temperature: 28°C
Min temperature: 18°C
======================================== saturday ========================================
Description: Sunny
Max temperature: 30°C
Min temperature: 19°C
======================================== sunday ========================================
Description: Partly Sunny
Max temperature: 29°C
Min temperature: 21°C
======================================== monday ========================================
Description: Partly Cloudy
Max temperature: 30°C
Min temperature: 19°C
======================================== tuesday ========================================
Description: Mostly Sunny
Max temperature: 26°C
Min temperature: 16°C
======================================== wednesday ========================================
Description: Mostly Sunny
Max temperature: 25°C
Min temperature: 19°CAlright, we are done with this tutorial, I hope this was helpful for you to understand how you can combine requests and BeautifulSoup to grab data from web pages.
By the way, there is another tutorial for extracting YouTube videos data in Python or accessing Wikipedia pages in Python!
Read also: How to Extract All Website Links in Python.
Happy Scraping ♥
Finished reading? Keep the learning going with our AI-powered Code Explainer. Try it now!
View Full Code Switch My Framework



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!