Step up your coding game with AI-powered Code Explainer. Get insights like never before!
Extracting all links of a web page is a common task among web scrapers. It is useful to build advanced scrapers that crawl every page of a certain website to extract data. It can also be used for the SEO diagnostics process or even the information gathering phase for penetration testers.
In this tutorial, you will learn how to build a link extractor tool in Python from Scratch using only requests and BeautifulSoup libraries.
Note that there are a lot of link extractors out there, such as Link Extractor by Sitechecker. The goal of this tutorial is to build one on your own using Python programming language.
Get: Ethical Hacking with Python EBook
Let's install the dependencies:
pip3 install requests bs4 coloramaWe'll be using requests to make HTTP requests conveniently, BeautifulSoup for parsing HTML, and colorama for changing text color.
Open up a new Python file and follow along. Let's import the modules we need:
import requests
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
import coloramaWe are going to use colorama just for using different colors when printing to distinguish between internal and external links:
# init the colorama module
colorama.init()
GREEN = colorama.Fore.GREEN
GRAY = colorama.Fore.LIGHTBLACK_EX
RESET = colorama.Fore.RESET
YELLOW = colorama.Fore.YELLOWWe gonna need two global variables, one for all internal links of the website and the other for all the external links:
# initialize the set of links (unique links)
internal_urls = set()
external_urls = set()- Internal links are URLs that link to other pages of the same website.
- External links are URLs that link to other websites.
Since not all links in anchor tags (a tags) are valid (I've experimented with this), some are links to parts of the website, and some are javascript, so let's write a function to validate URLs:
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)This will ensure that a proper scheme (protocol, e.g http or https) and domain name exist in the URL.
Now, let's build a function to return all the valid URLs of a web page:
def get_all_website_links(url):
"""
Returns all URLs that is found on `url` in which it belongs to the same website
"""
# all URLs of `url`
urls = set()
# domain name of the URL without the protocol
domain_name = urlparse(url).netloc
soup = BeautifulSoup(requests.get(url).content, "html.parser")First, I initialized the urls set variable; I've used Python sets here because we don't want redundant links.
Second, I've extracted the domain name from the URL. We gonna need it to check whether the link we grabbed is external or internal.
Third, I've downloaded the HTML content of the web page and wrapped it with a soup object to ease HTML parsing.
Let's get all HTML a tags (anchor tags that contain all the links of the web page):
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
if href == "" or href is None:
# href empty tag
continueSo we get the href attribute and check if there is something there. Otherwise, we just continue to the next link.
Since not all links are absolute, we gonna need to join relative URLs with their domain name (e.g when the href is "/search" and the url is "google.com", the result will be "google.com/search"):
# join the URL if it's relative (not absolute link)
href = urljoin(url, href)Now, we need to remove HTTP GET parameters from the URLs since this will cause redundancy in the set. The below code handles that:
parsed_href = urlparse(href)
# remove URL GET parameters, URL fragments, etc.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.pathLet's finish up the function:
if not is_valid(href):
# not a valid URL
continue
if href in internal_urls:
# already in the set
continue
if domain_name not in href:
# external link
if href not in external_urls:
print(f"{GRAY}[!] External link: {href}{RESET}")
external_urls.add(href)
continue
print(f"{GREEN}[*] Internal link: {href}{RESET}")
urls.add(href)
internal_urls.add(href)
return urlsRelated: Ethical Hacking with Python EBook
All we did here was checking:
- If the URL isn't valid, continue to the next link.
- If the URL is already in the
internal_urls, we don't need that either. - If the URL is an external link, print it in gray color, add it to our global
external_urlsset, and continue to the next link.
Finally, after all checks, the URL will be an internal link. We print it and add it to our urls and internal_urls sets.
The above function will only grab the links of one specific page; what if we want to extract all the links for the entire website? Let's do this:
# number of urls visited so far will be stored here
total_urls_visited = 0
def crawl(url, max_urls=30):
"""
Crawls a web page and extracts all links.
You'll find all links in `external_urls` and `internal_urls` global set variables.
params:
max_urls (int): number of max urls to crawl, default is 30.
"""
global total_urls_visited
total_urls_visited += 1
print(f"{YELLOW}[*] Crawling: {url}{RESET}")
links = get_all_website_links(url)
for link in links:
if total_urls_visited > max_urls:
break
crawl(link, max_urls=max_urls)This function crawls the website, which means it gets all the links of the first page and then calls itself recursively to follow all the links extracted previously. However, this can cause some issues; the program will get stuck on large websites (that have many links), such as google.com. As a result, I've added a max_urls parameter to exit when we reach a certain number of URLs checked.
Alright, let's test this; make sure you use this on a website you're authorized to. Otherwise, I'm not responsible for any harm you cause.
if __name__ == "__main__":
crawl("https://www.thepythoncode.com")
print("[+] Total Internal links:", len(internal_urls))
print("[+] Total External links:", len(external_urls))
print("[+] Total URLs:", len(external_urls) + len(internal_urls))
print("[+] Total crawled URLs:", max_urls)Get our Ethical Hacking with Python EBook
I'm testing it on our website. However, I highly encourage you not to do that; that will cause a lot of requests as it will crowd our little web server and block your IP address.
Here is a part of the output:
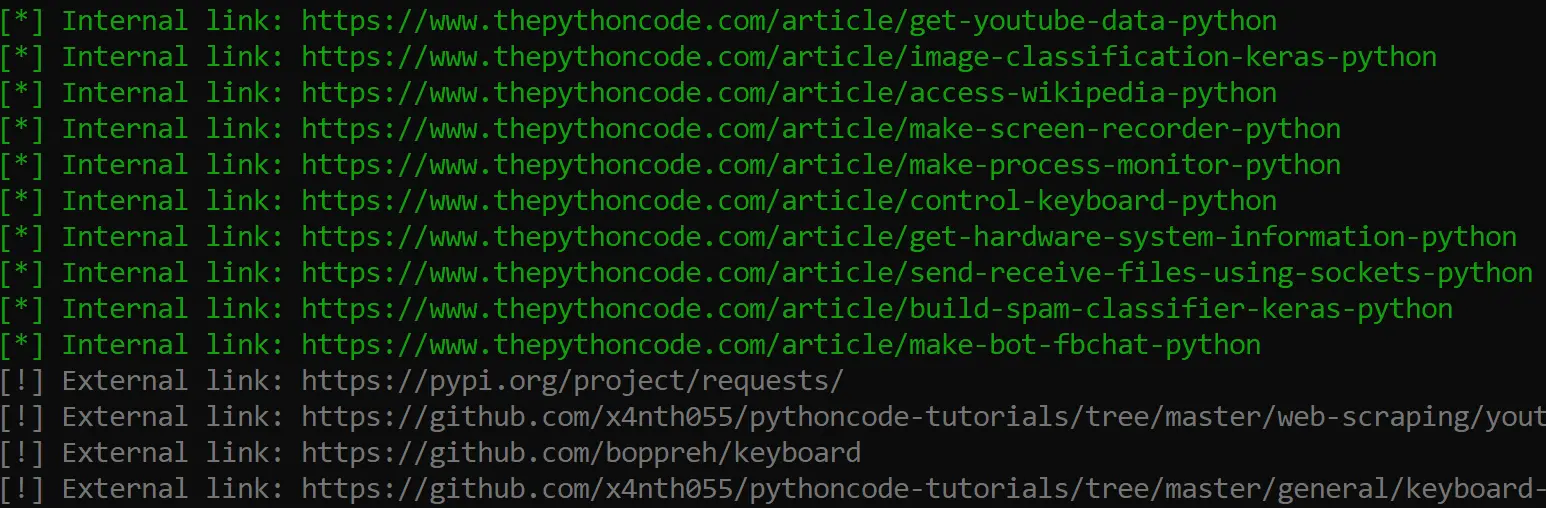
After the crawling finishes, it'll print the total links extracted and crawled:
[+] Total Internal links: 90
[+] Total External links: 137
[+] Total URLs: 227
[+] Total crawled URLs: 30Awesome, right? I hope this tutorial was a benefit for you and inspired you to build such tools using Python.
Some websites load most of their content using JavaScript. Therefore, we need to use the requests_html library instead, which enables us to execute Javascript using Chromium; I already wrote a script for that by adding just a few lines (as requests_html is quite similar to requests). Check it out here.
Requesting the same website many times in a short period may cause the website to block your IP address. In that case, you need to use a proxy server for such purposes.
If you're interested in grabbing images instead, check this tutorial: How to Download All Images from a Web Page in Python, or if you want to extract HTML tables, check this tutorial.
I edited the code a little bit so you can save the output URLs in a file and pass URLs from command line arguments. I highly suggest you check the complete code here.
In our Ethical Hacking with Python EBook, we have used this code to build an advanced email spider that goes into every link extracted and searches for email addresses. Make sure to check it out here!
Happy Scraping ♥
Take the stress out of learning Python. Meet our Python Code Assistant – your new coding buddy. Give it a whirl!
View Full Code Auto-Generate My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!