Before we get started, have you tried our new Python Code Assistant? It's like having an expert coder at your fingertips. Check it out!
One of the most challenging tasks in web scraping is being able to log in automatically and extract data within your account on that website. In this tutorial, you will learn how you can extract all forms from web pages and fill and submit them using requests_html and BeautifulSoup libraries.
To get started, let's install them:
pip3 install requests_html bs4Related: How to Automate Login using Selenium in Python.
Extracting Forms from Web Pages
Open up a new file. I'm calling it form_extractor.py:
from bs4 import BeautifulSoup
from requests_html import HTMLSession
from pprint import pprintTo start, we need a way to make sure that after making requests to the target website, we're storing the cookies provided by that website so that we can persist the session:
# initialize an HTTP session
session = HTMLSession()Now the session variable is a consumable session for cookie persistence; we will use this variable everywhere in our code. Let's write a function that given a URL, requests that page, extracts all HTML form tags from it, and then return them (as a list):
def get_all_forms(url):
"""Returns all form tags found on a web page's `url` """
# GET request
res = session.get(url)
# for javascript driven website
# res.html.render()
soup = BeautifulSoup(res.html.html, "html.parser")
return soup.find_all("form")You may notice that I commented that res.html.render() line executes Javascript before trying to extract anything, as some websites load their content dynamically using Javascript, uncomment it if you feel that the website is using Javascript to load forms.
So the above function will be able to extract all forms from a web page, but we need a way to extract each form's details, such as inputs, form method (GET, POST, DELETE, etc.) and action (target URL for form submission), the below function does that:
def get_form_details(form):
"""Returns the HTML details of a form,
including action, method and list of form controls (inputs, etc)"""
details = {}
# get the form action (requested URL)
action = form.attrs.get("action").lower()
# get the form method (POST, GET, DELETE, etc)
# if not specified, GET is the default in HTML
method = form.attrs.get("method", "get").lower()
# get all form inputs
inputs = []
for input_tag in form.find_all("input"):
# get type of input form control
input_type = input_tag.attrs.get("type", "text")
# get name attribute
input_name = input_tag.attrs.get("name")
# get the default value of that input tag
input_value =input_tag.attrs.get("value", "")
# add everything to that list
inputs.append({"type": input_type, "name": input_name, "value": input_value})The above is only responsible for extracting the input HTML tags. Let's extract selects and textareas as well:
for select in form.find_all("select"):
# get the name attribute
select_name = select.attrs.get("name")
# set the type as select
select_type = "select"
select_options = []
# the default select value
select_default_value = ""
# iterate over options and get the value of each
for select_option in select.find_all("option"):
# get the option value used to submit the form
option_value = select_option.attrs.get("value")
if option_value:
select_options.append(option_value)
if select_option.attrs.get("selected"):
# if 'selected' attribute is set, set this option as default
select_default_value = option_value
if not select_default_value and select_options:
# if the default is not set, and there are options, take the first option as default
select_default_value = select_options[0]
# add the select to the inputs list
inputs.append({"type": select_type, "name": select_name, "values": select_options, "value": select_default_value})
for textarea in form.find_all("textarea"):
# get the name attribute
textarea_name = textarea.attrs.get("name")
# set the type as textarea
textarea_type = "textarea"
# get the textarea value
textarea_value = textarea.attrs.get("value", "")
# add the textarea to the inputs list
inputs.append({"type": textarea_type, "name": textarea_name, "value": textarea_value})The first for loop extracts all the select tags in the form. We also get all available options and add them to the form details. The second loop is about finding textarea tags and adding them to form details as well, finishing the function:
# put everything to the resulting dictionary
details["action"] = action
details["method"] = method
details["inputs"] = inputs
return detailsNote: You can always check the entire code on this page.
Now let's try out these functions before we dive into submitting forms:
if __name__ == "__main__":
import sys
# get URL from the command line
url = sys.argv[1]
# get all form tags
forms = get_all_forms(url)
# iteratte over forms
for i, form in enumerate(forms, start=1):
form_details = get_form_details(form)
print("="*50, f"form #{i}", "="*50)
print(form_details)I've used enumerate() just for numerating extracted forms. Let's save the Python file as form_extractor.py and run it:
$ python form_extractor.py https://wikipedia.orgHere is the output in the case of the home page of Wikipedia:
================================================== form #1 ==================================================
{'action': '//www.wikipedia.org/search-redirect.php',
'inputs': [{'name': 'family', 'type': 'hidden', 'value': 'Wikipedia'},
{'name': 'language', 'type': 'hidden', 'value': 'en'},
{'name': 'search', 'type': 'search', 'value': ''},
{'name': 'go', 'type': 'hidden', 'value': 'Go'},
{'name': 'language',
'type': 'select',
'value': 'en',
'values': ['af', 'pl', 'sk', 'ar', 'ast', 'az', 'bg', 'nan', 'bn', 'be', 'ca', 'cs', 'cy', 'da', 'de', 'et', 'el', 'en', 'es', 'eo', 'eu', 'fa', 'fr', 'gl', 'hy', 'hi', 'hr', 'id', 'it', 'he', 'ka', 'la', 'lv', 'lt', 'hu', 'mk', 'arz', 'ms', 'min', 'nl', 'ja', 'no', 'nn', 'ce', 'uz', 'pt', 'kk', 'ro', 'ru', 'simple', 'ceb', 'sl', 'sr', 'sh', 'sv', 'ta', 'tt', 'th', 'tg', 'azb', 'tr', 'uk', 'ur', 'vi', 'vo', 'war', 'zh-yue', 'zh','my']}],
'method': 'get'}As you can see, if you try to go into that page using your browser, you'll see a simple Wikipedia search box. That's why we see only one form here.
Learn also: How to Download All Images from a Web Page in Python.
Submitting Web Forms
You can also notice that most of the input fields extracted earlier got the hidden type; we're not interested in that. Instead, we need to fill the input in which it has the name of "search" and type of "search", that's the only visible field for the typical user. More generally, we look for any input field that is not hidden for the user, including select and textarea fields.
Open up a new Python file. I'll call it form_submitter.py and import the libraries we're going to need:
from bs4 import BeautifulSoup
from pprint import pprint
from urllib.parse import urljoin
import webbrowser
import sys
from form_extractor import get_all_forms, get_form_details, sessionWe're grabbing the functions we did earlier from the form_extractor.py file, let's start using them.
First, let us extract all available forms and print them into the screen:
# get the URL from the command line
url = sys.argv[1]
all_forms = get_all_forms(url)
# get the first form (edit this as you wish)
# first_form = get_all_forms(url)[0]
for i, f in enumerate(all_forms, start=1):
form_details = get_form_details(f)
print(f"{i} #")
pprint(form_details)
print("="*50)Now to make our code as flexible as possible (in which we can run for any website), let's prompt the user of the script to choose which form to submit:
choice = int(input("Enter form indice: "))
# extract all form details
form_details = get_form_details(all_forms[choice-1])
pprint(form_details)Now let's construct our submission data:
# the data body we want to submit
data = {}
for input_tag in form_details["inputs"]:
if input_tag["type"] == "hidden":
# if it's hidden, use the default value
data[input_tag["name"]] = input_tag["value"]
elif input_tag["type"] == "select":
for i, option in enumerate(input_tag["values"], start=1):
# iterate over available select options
if option == input_tag["value"]:
print(f"{i} # {option} (default)")
else:
print(f"{i} # {option}")
choice = input(f"Enter the option for the select field '{input_tag['name']}' (1-{i}): ")
try:
choice = int(choice)
except:
# choice invalid, take the default
value = input_tag["value"]
else:
value = input_tag["values"][choice-1]
data[input_tag["name"]] = value
elif input_tag["type"] != "submit":
# all others except submit, prompt the user to set it
value = input(f"Enter the value of the field '{input_tag['name']}' (type: {input_tag['type']}): ")
data[input_tag["name"]] = valueSo the above code will use the default value of the hidden fields (such as CSRF token) and prompt the user for other input fields (such as search, email, text, and others). It will also prompt the user to choose from the available select options.
Let's see how we can submit it based on the method:
# join the url with the action (form request URL)
url = urljoin(url, form_details["action"])
# pprint(data)
if form_details["method"] == "post":
res = session.post(url, data=data)
elif form_details["method"] == "get":
res = session.get(url, params=data)I used only GET or POST here, but you can extend this for other HTTP methods such as PUT and DELETE (using session.put() and session.delete() methods respectively).
Alright, now we have res variable that contains the HTTP response; this should contain the web page that the server sent after form submission; let's make sure it worked. The below code prepares the HTML content of the web page to save it on our local computer:
# the below code is only for replacing relative URLs to absolute ones
soup = BeautifulSoup(res.content, "html.parser")
for link in soup.find_all("link"):
try:
link.attrs["href"] = urljoin(url, link.attrs["href"])
except:
pass
for script in soup.find_all("script"):
try:
script.attrs["src"] = urljoin(url, script.attrs["src"])
except:
pass
for img in soup.find_all("img"):
try:
img.attrs["src"] = urljoin(url, img.attrs["src"])
except:
pass
for a in soup.find_all("a"):
try:
a.attrs["href"] = urljoin(url, a.attrs["href"])
except:
pass
# write the page content to a file
open("page.html", "w").write(str(soup))All this is doing is replacing relative URLs (such as /wiki/Programming_language) with absolute URLs (such as https://www.wikipedia.org/wiki/Programming_language), so we can adequately browse the page locally in our computer. I've saved all the content into a local file "page.html", let's open it in our browser:
import webbrowser
# open the page on the default browser
webbrowser.open("page.html") Alright, the code is done. Here is how I executed this:
================================================== form #1 ==================================================
{'action': '//www.wikipedia.org/search-redirect.php',
'inputs': [{'name': 'family', 'type': 'hidden', 'value': 'Wikipedia'},
{'name': 'language', 'type': 'hidden', 'value': 'en'},
{'name': 'search', 'type': 'search', 'value': ''},
{'name': 'go', 'type': 'hidden', 'value': 'Go'},
{'name': 'language',
'type': 'select',
'value': 'en',
'values': ['af', 'pl', 'sk', 'ar', 'ast', 'az', 'bg', 'nan', 'bn', 'be', 'ca', 'cs', 'cy', 'da', 'de', 'et', 'el', 'en', 'es', 'eo', 'eu', 'fa', 'fr', 'gl', 'hy', 'hi', 'hr', 'id', 'it', 'he', 'ka', 'la', 'lv', 'lt', 'hu', 'mk', 'arz', 'ms', 'min', 'nl', 'ja', 'no', 'nn', 'ce', 'uz', 'pt', 'kk', 'ro', 'ru', 'simple', 'ceb', 'sl', 'sr', 'sh', 'sv', 'ta', 'tt', 'th', 'tg', 'azb', 'tr', 'uk', 'ur', 'vi', 'vo', 'war', 'zh-yue', 'zh','my']}],
'method': 'get'}
Enter form indice: 1
{'action': '//www.wikipedia.org/search-redirect.php',
'inputs': [{'name': 'family', 'type': 'hidden', 'value': 'Wikipedia'},
{'name': 'language', 'type': 'hidden', 'value': 'en'},
{'name': 'search', 'type': 'search', 'value': ''},
{'name': 'go', 'type': 'hidden', 'value': 'Go'},
{'name': 'language',
'type': 'select',
'value': 'en',
'values': ['af', 'pl', 'sk', 'ar', 'ast', 'az', 'bg', 'nan', 'bn', 'be', 'ca', 'cs', 'cy', 'da', 'de', 'et', 'el', 'en', 'es', 'eo', 'eu', 'fa', 'fr', 'gl', 'hy', 'hi', 'hr', 'id', 'it', 'he', 'ka', 'la', 'lv', 'lt', 'hu', 'mk', 'arz', 'ms', 'min', 'nl', 'ja', 'no', 'nn', 'ce', 'uz', 'pt', 'kk', 'ro', 'ru', 'simple', 'ceb', 'sl', 'sr', 'sh', 'sv', 'ta', 'tt', 'th', 'tg', 'azb', 'tr', 'uk', 'ur', 'vi', 'vo', 'war', 'zh-yue', 'zh','my']}],
'method': 'get'}
Enter the value of the field 'search' (type: search): python programming language
1 # af
2 # pl
3 # sk
4 # ar
5 # ast
...
<SNIPPED>
18 # en (default)
19 # es
...
<SNIPPED>
67 # vo
68 # war
69 # zh-yue
70 # zh
71 # my
Enter the option for the select field 'language' (1-71): 4In the beginning, the script prompted me to choose from the list of forms. In our case, there is only one form. After that, it prompted me for all the available non-hidden forms, which are the search and language select field.
This is basically the same as manually filling the form in the web browser and choosing the language:
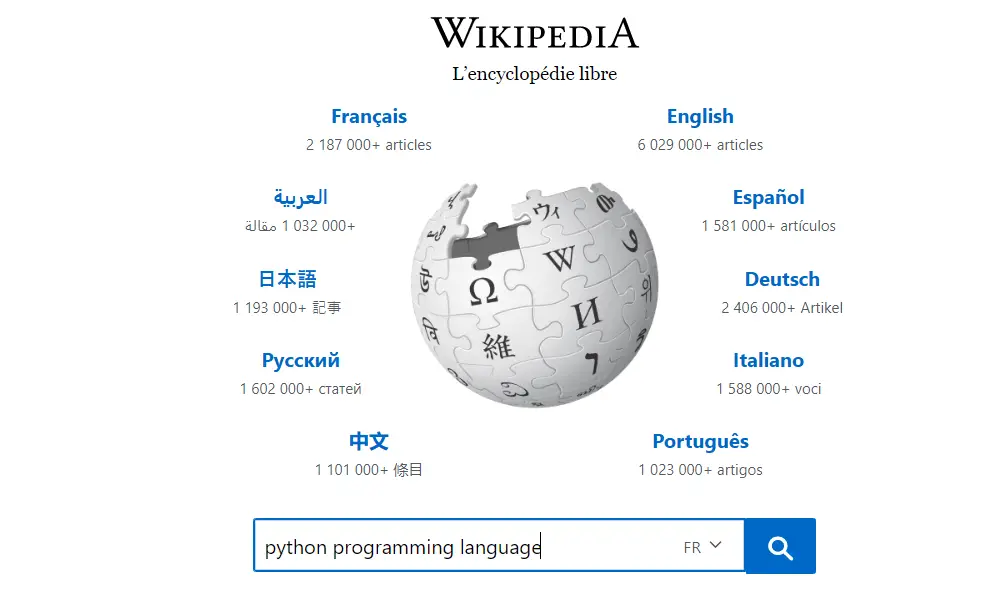
After I hit enter in my code execution, this will submit the form, save the result page locally and automatically open it in the default web browser:
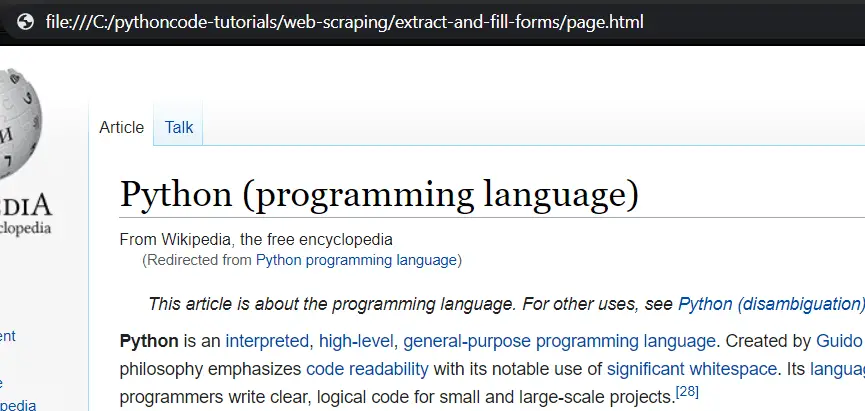
This is how Python saw the result, so we successfully submitted the search form automatically and loaded the result page with the help of Python!
Conclusion
Alright, that's it. In this tutorial, we searched Wikipedia. Still, as mentioned earlier, you can use it on any form you want, especially for login forms, in which you can log in and continue to extract data that requires user authentication.
See how you can extend this. For instance, you can try to make a submitter for all forms (since we used only the first form here), or you can make a sophisticated crawler that extracts all website links and finds all forms of a particular website. However, keep in mind that a website can ban your IP address if you request many pages within a short time. In that case, you can slow down your crawler or use a proxy.
Also, you can extend this code by automating login using Selenium. Check this tutorial on how you can do that!
You can get the complete code of this tutorial here.
Want to Learn More about Web Scraping?
Finally, if you want to dig more into web scraping with different Python libraries, not just BeautifulSoup, the below courses will definitely be valuable for you:
- Modern Web Scraping with Python using Scrapy Splash Selenium.
- Web Scraping and API Fundamentals in Python.
Further learning: How to Convert HTML Tables into CSV Files in Python.
Happy Scraping ♥
Found the article interesting? You'll love our Python Code Generator! Give AI a chance to do the heavy lifting for you. Check it out!
View Full Code Assist My Coding



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!