Get a head start on your coding projects with our Python Code Generator. Perfect for those times when you need a quick solution. Don't wait, try it today!
Have you ever wanted to automatically extract HTML tables from web pages and save them in a proper format on your computer? If that's the case, then you're in the right place. In this tutorial, we will be using requests and BeautifulSoup libraries to convert any table on any web page and save it on our disk.
We will also use pandas to easily convert to CSV format (or any format that pandas support). If you haven't requests, BeautifulSoup and pandas installed, then install them with the following command:
pip3 install requests bs4 pandasIf you want to do the other way around, converting Pandas data frames to HTML tables, then check this tutorial.
Open up a new Python file and follow along. Let's import the libraries:
import requests
import pandas as pd
from bs4 import BeautifulSoup as bsWe need a function that accepts the target URL and gives us the proper soup object:
USER_AGENT = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
# US english
LANGUAGE = "en-US,en;q=0.5"
def get_soup(url):
"""Constructs and returns a soup using the HTML content of `url` passed"""
# initialize a session
session = requests.Session()
# set the User-Agent as a regular browser
session.headers['User-Agent'] = USER_AGENT
# request for english content (optional)
session.headers['Accept-Language'] = LANGUAGE
session.headers['Content-Language'] = LANGUAGE
# make the request
html = session.get(url)
# return the soup
return bs(html.content, "html.parser")We first initialize a requests session, we use the User-Agent header to indicate that we are just a regular browser and not a bot (some websites block them), and then we get the HTML content using session.get() method. After that, we construct a BeautifulSoup object using html.parser.
Related tutorial: How to Make an Email Extractor in Python.
Since we want to extract every table on any page, we need to find the table HTML tag and return it. The following function does exactly that:
def get_all_tables(soup):
"""Extracts and returns all tables in a soup object"""
return soup.find_all("table")Now we need a way to get the table headers, the column names, or whatever you want to call them:
def get_table_headers(table):
"""Given a table soup, returns all the headers"""
headers = []
for th in table.find("tr").find_all("th"):
headers.append(th.text.strip())
return headersThe above function finds the first row of the table and extracts all the th tags (table headers).
Now that we know how to extract table headers, the remaining is to extract all the table rows:
def get_table_rows(table):
"""Given a table, returns all its rows"""
rows = []
for tr in table.find_all("tr")[1:]:
cells = []
# grab all td tags in this table row
tds = tr.find_all("td")
if len(tds) == 0:
# if no td tags, search for th tags
# can be found especially in wikipedia tables below the table
ths = tr.find_all("th")
for th in ths:
cells.append(th.text.strip())
else:
# use regular td tags
for td in tds:
cells.append(td.text.strip())
rows.append(cells)
return rowsAll the above function is doing, is to find tr tags (table rows) and extract td elements which then appends them to a list. The reason we used table.find_all("tr")[1:] and not all tr tags, is because the first tr tag corresponds to the table headers; we don't wanna add it here.
The below function takes the table name, table headers, and all the rows and saves them in CSV format:
def save_as_csv(table_name, headers, rows):
pd.DataFrame(rows, columns=headers).to_csv(f"{table_name}.csv")Now that we have all the core functions, let's bring them all together in the main() function:
def main(url):
# get the soup
soup = get_soup(url)
# extract all the tables from the web page
tables = get_all_tables(soup)
print(f"[+] Found a total of {len(tables)} tables.")
# iterate over all tables
for i, table in enumerate(tables, start=1):
# get the table headers
headers = get_table_headers(table)
# get all the rows of the table
rows = get_table_rows(table)
# save table as csv file
table_name = f"table-{i}"
print(f"[+] Saving {table_name}")
save_as_csv(table_name, headers, rows)The above function does the following:
- Parsing the HTML content of the web page given its URL by constructing the BeautifulSoup object.
- Finding all the tables on that HTML page.
- Iterating over all these extracted tables and saving them one by one.
Finally, let's call the main function:
if __name__ == "__main__":
import sys
try:
url = sys.argv[1]
except IndexError:
print("Please specify a URL.\nUsage: python html_table_extractor.py [URL]")
exit(1)
main(url)This will accept the URL from the command line arguments. Let's try to see if this is working:
C:\pythoncode-tutorials\web-scraping\html-table-extractor>python html_table_extractor.py https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population
[+] Found a total of 2 tables.
[+] Saving table-1
[+] Saving table-2Nice, two CSV files appeared in my current directory that correspond to the two tables in that Wikipedia page. Here is a part of one of the tables extracted:
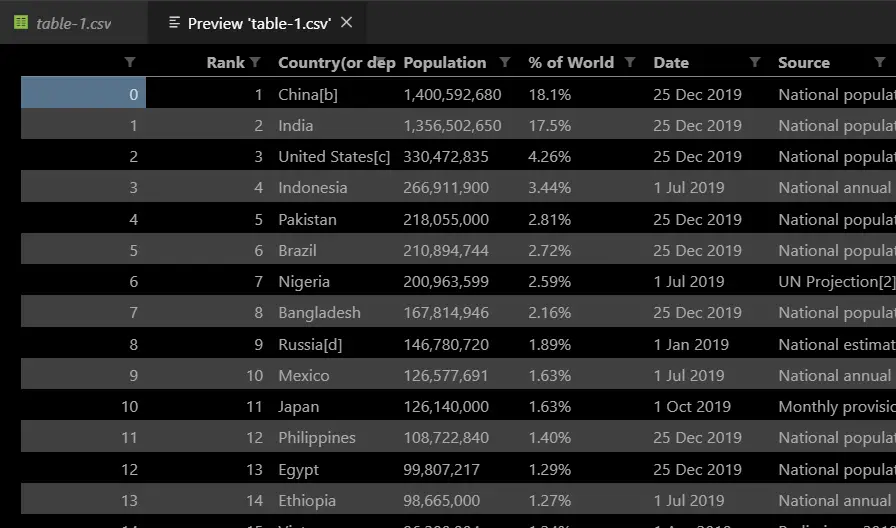
Awesome! We have successfully built a Python script to extract any table from any website, try to pass other URLs, and see if it's working.
For Javascript-driven websites (which load the website data dynamically using Javascript), try to use requests-html library or selenium instead. Let us see what you did in the comments below!
You can also make a web crawler that downloads all tables from an entire website. You can do that by extracting all website links and running this script on each URL you got from it.
Also, if, for whatever reason, the website you're scraping blocks your IP address, you need to use some proxy server as a countermeasure.
Read also: How to Extract and Submit Web Forms from a URL using Python.
Happy Scraping ♥
Found the article interesting? You'll love our Python Code Generator! Give AI a chance to do the heavy lifting for you. Check it out!
View Full Code Assist My Coding



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!