Unlock the secrets of your code with our AI-powered Code Explainer. Take a look!
There are a lot of online tools that provide converting HTML to PDF documents, and most of them are free. In this tutorial, you will learn how you can do that with Python.
We will use the wkhtmltopdf tool, an open-source command-line utility that renders HTML into PDF using the Qt WebKit rendering engine.
Here is the table of contents of this tutorial:
- Installing wkhtmltopdf
- Converting HTML from URL to PDF
- Converting Local HTML File to PDF
- Converting HTML String to PDF
To get started, we have to install wkhtmltopdf tool, and its pdfkit wrapper in Python.
Download: Practical Python PDF Processing EBook.
Installing wkhtmltopdf
On Windows
Go to the wkhtmltopdf official downloads page, and download the Windows installer for your Windows architecture. In my case, I downloaded the 64-bit architecture one that is supported on Vista or later since I have Windows 10.
After you have downloaded the installer and successfully installed the wkhtmltopdf tool, you need to add it to the PATH environment variable.
To do it, you must go to Windows search and write "environment", you'll see "Edit the system environment variables", click on it:
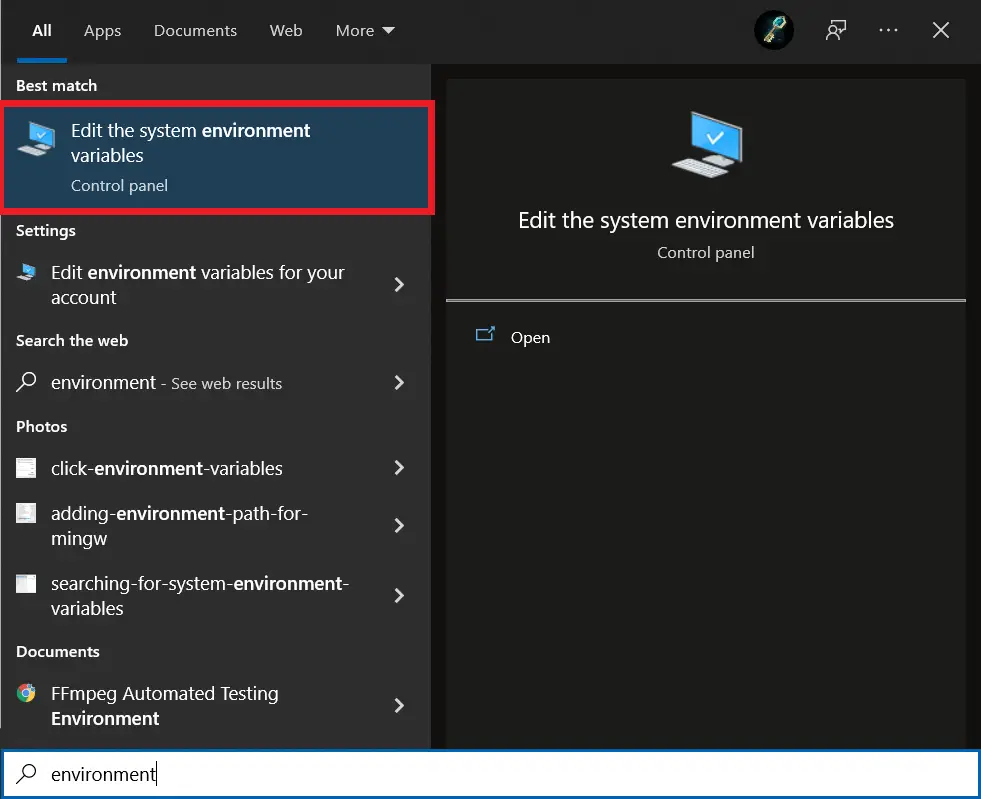 َA new window will appear, and click on "Environment Variables...":
َA new window will appear, and click on "Environment Variables...":
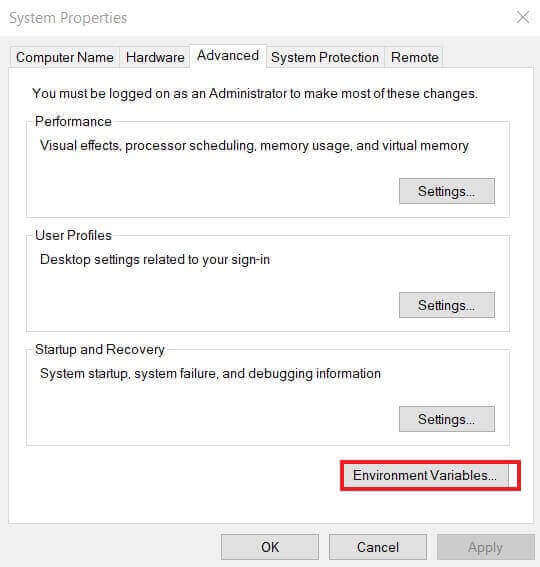 In the new window, you're free to choose the system or user variables and find the PATH variable to edit:
In the new window, you're free to choose the system or user variables and find the PATH variable to edit:
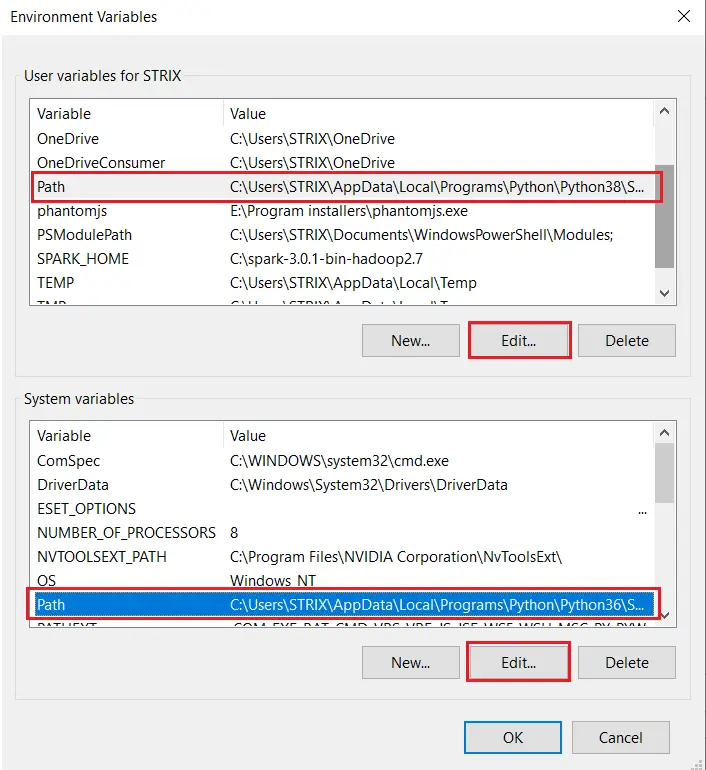 Once you click on Edit on either variable, go on and add the path of where you've installed wkhtmltopdf to the PATH variable:
Once you click on Edit on either variable, go on and add the path of where you've installed wkhtmltopdf to the PATH variable:
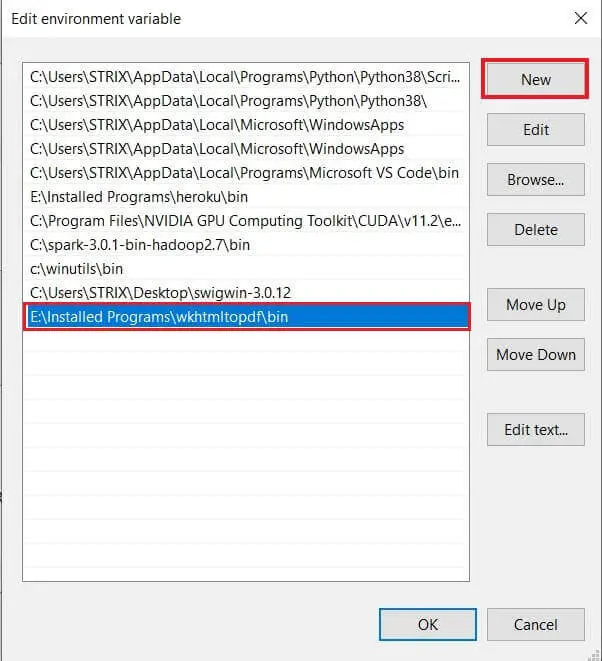 After that, click the OK button and close the previous windows, and you're good to go.
After that, click the OK button and close the previous windows, and you're good to go.
On Linux
If you're on Linux, it's much more straightforward as it'll be added to PATH automatically using your package manager.
Below is the command for Ubuntu/Debian:
$ apt update
$ apt install wkhtmltopdfAnd below is for Debian/CentOS:
$ sudo yum makecache --refresh
$ sudo yum -y install wkhtmltopdf
On macOS
You can install it using Brew:
$ brew install Caskroom/cask/wkhtmltopdfGet Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookConverting HTML from URL to PDF
pdfkit did a great job wrapping wkhtmltopdf in Python; we use effortless methods to do such complicated tasks. Let's install it:
$ pip install pdfkitFor instance, let's convert the Google search page to a PDF document:
import pdfkit
# directly from url
pdfkit.from_url("https://google.com", "google.pdf", verbose=True)
print("="*50)The first argument to the from_url() function is the URL you want to convert; the second argument is the PDF document name you wish to generate. Here's the output PDF document:
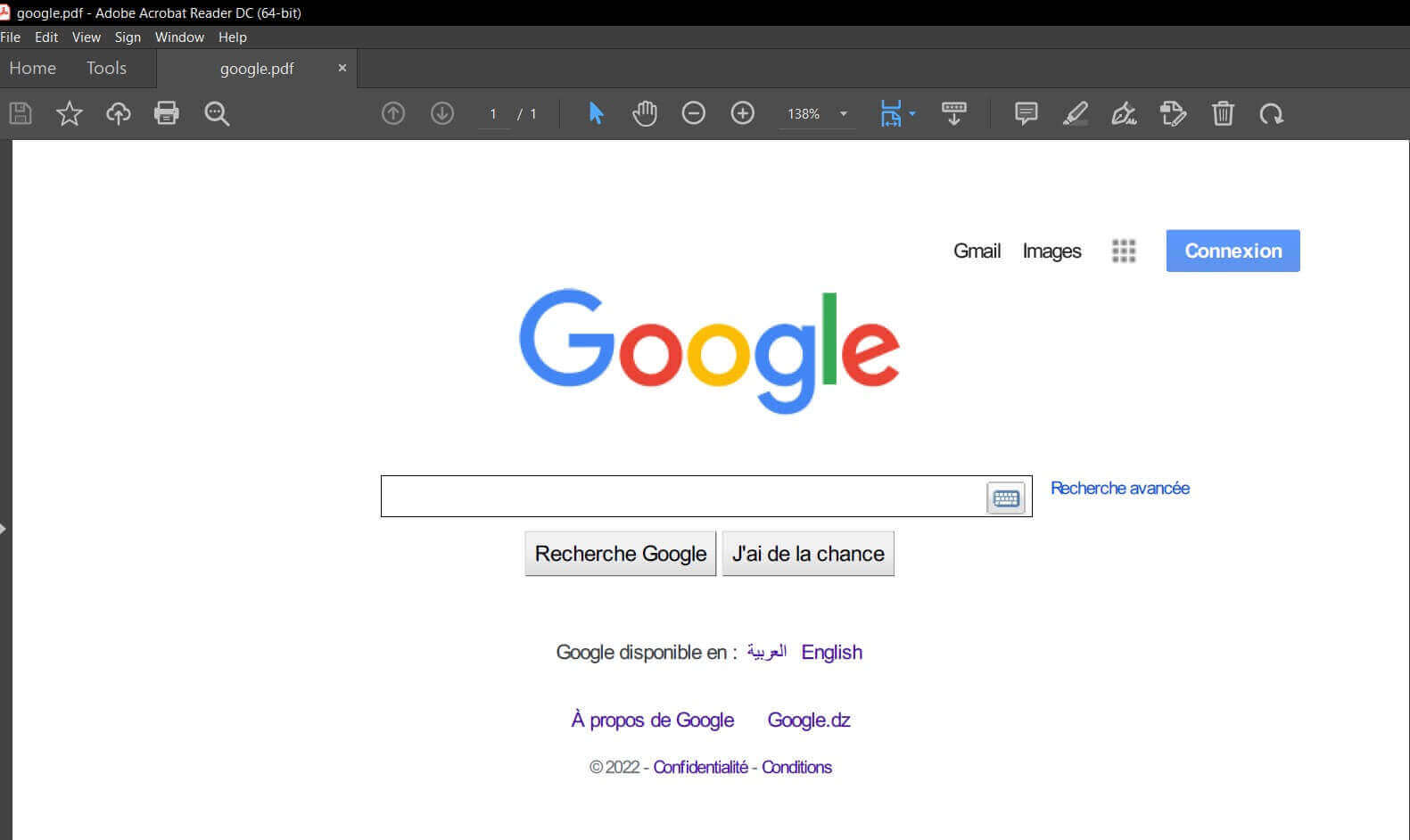
Converting Local HTML File to PDF
You can also convert a local HTML file in your machine to a PDF document; here's how:
# from file
pdfkit.from_file("webapp/index.html", "index.pdf", verbose=True, options={"enable-local-file-access": True})
print("="*50)The webapp/ folder (in which you can view it here) contains the index.html, its style.css CSS file, and a sample image image.png.
Here's the content of index.html:
<!DOCTYPE html>
<!--[if lt IE 7]> <html class="no-js lt-ie9 lt-ie8 lt-ie7"> <![endif]-->
<!--[if IE 7]> <html class="no-js lt-ie9 lt-ie8"> <![endif]-->
<!--[if IE 8]> <html class="no-js lt-ie9"> <![endif]-->
<!--[if gt IE 8]> <html class="no-js"> <!--<![endif]-->
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title></title>
<meta name="description" content="">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="style.css">
<style>
table, th, td {
border: 1px solid black;
}
</style>
</head>
<body>
<!--[if lt IE 7]>
<p class="browsehappy">You are using an <strong>outdated</strong> browser. Please <a href="#">upgrade your browser</a> to improve your experience.</p>
<![endif]-->
<img src="image.png" alt="Python logo">
<p>Sample text here. Random HTML table that is styled with CSS:</p>
<table bordered>
<thead>
<th>ID</th>
<th>Name</th>
</thead>
<tbody>
<tr>
<td>1</td>
<td>Abdou</td>
</tr>
<tr>
<td>2</td>
<td>Rockikz</td>
</tr>
<tr>
<td>3</td>
<td>John</td>
</tr>
<tr>
<td>3</td>
<td>Doe</td>
</tr>
</tbody>
</table>
<p class="red-text">This should be a red paragraph.</p>
</body>
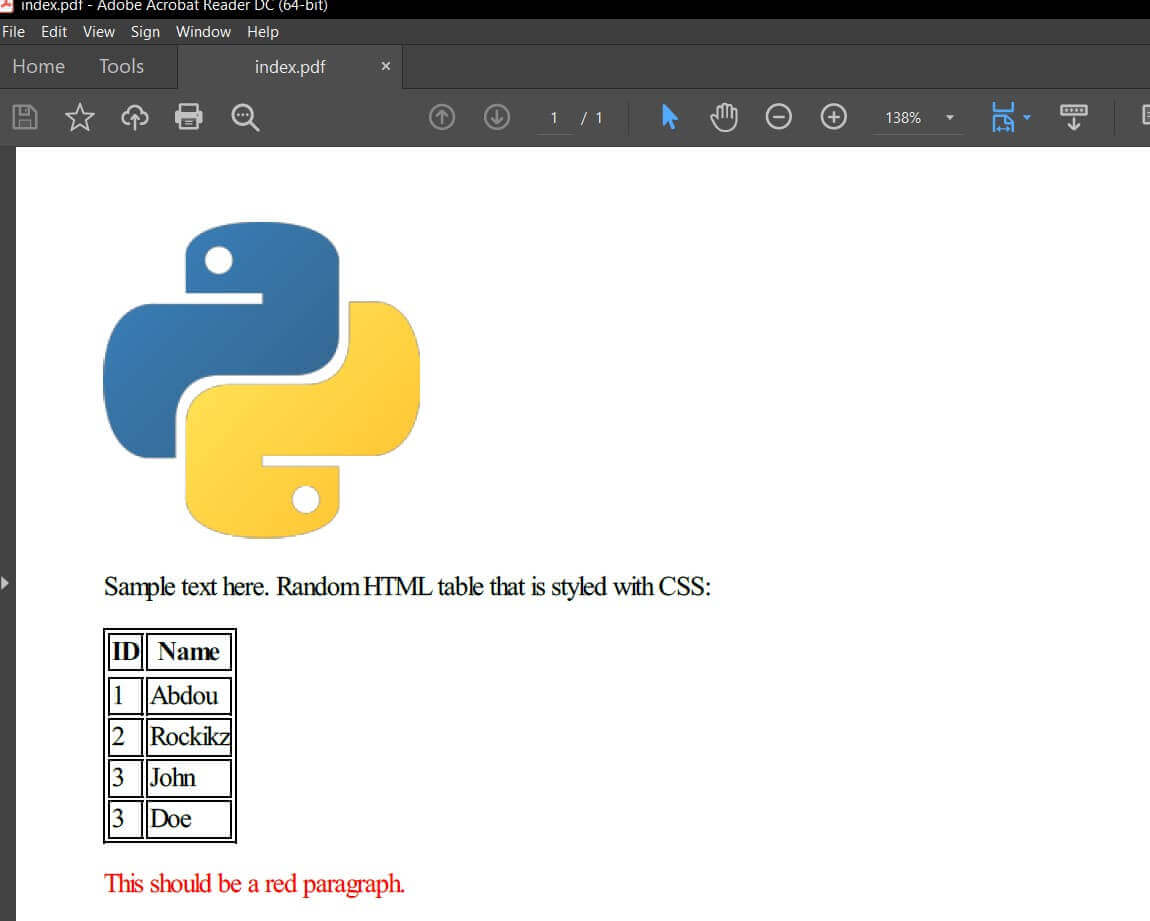
</html>We use the from_file() function, the first argument is the location of the HTML file, and the second is the resulting PDF document path, we set the enable-local-file-access to True in the options parameter to allow local file access from this HTML file to images and CSS/JS files.
Here's the content of index.pdf:
Converting HTML String to PDF
Finally, you can also convert HTML content from a Python string to a PDF document:
# from HTML content
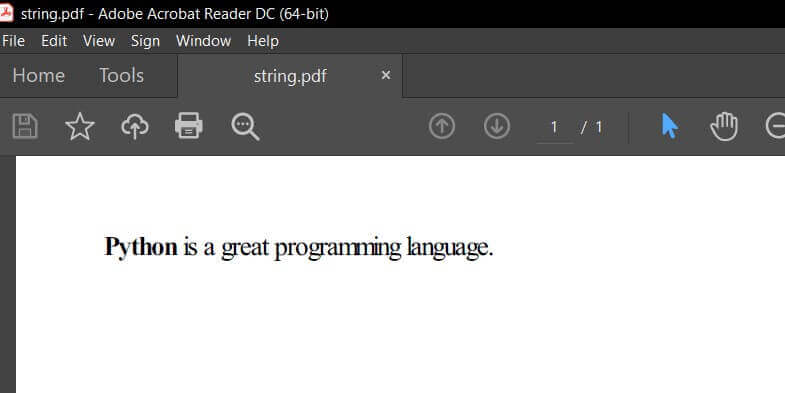
pdfkit.from_string("<p><b>Python</b> is a great programming language.</p>", "string.pdf", verbose=True)
print("="*50)Here's the content of string.pdf:
Get Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookConclusion
Awesome, I hope this tutorial was helpful to get you started with the wkhtmltopdf tool that helps convert HTML from a URL, local file, or string to a PDF document in Python with the help of pdfkit wrapper library.
You can get the complete code here.
Here are some PDF-related tutorials:
- How to Make a PDF Viewer in Python
- How to Convert PDF to Docx in Python
- How to Extract All PDF Links in Python
- How to Extract PDF Tables in Python
For more PDF handling guides on Python, you can check our Practical Python PDF Processing EBook, where we dive deeper into PDF document manipulation with Python, make sure to check it out here if you're interested!
Happy coding ♥
Let our Code Converter simplify your multi-language projects. It's like having a coding translator at your fingertips. Don't miss out!
View Full Code Fix My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!