Get a head start on your coding projects with our Python Code Generator. Perfect for those times when you need a quick solution. Don't wait, try it today!
As systems scale and migrate, fighting fraudsters has become a paramount challenge which is best addressed using real-time stream processing technologies.
For the purpose of this tutorial, we will build from scratch a real-time fraud detection system where we will generate a stream of fictitious transactions and synchronously analyze them to detect which ones are fraudulent.
Prerequisites
As our requirements stand, we need a reliable, scalable and fault-tolerant event streaming platform that stores our input events or transactions and process results. Apache Kafka is an open source distributed streaming platform that responds exactly to this need.
Apache Kafka can be downloaded from its official site, installing and running Apache Kafka on your operating system is outside the scope of this tutorial. However, you can check this guide that shows how to install it on Ubuntu (or any Debian-based distribution).
After you have everything setup, you can check the following:
- A Zookeeper instance is running on TCP port 2181.
- A Kafka instance is running and bound to TCP port 9092.
If the above mentioned controls are fulfilled, then now you have a single-node Kafka cluster up and running.
Creating the Application Skeleton
We can start now building our real-time fraud detection application using Kafka's consumer and producer APIs.
Our application will consist of:
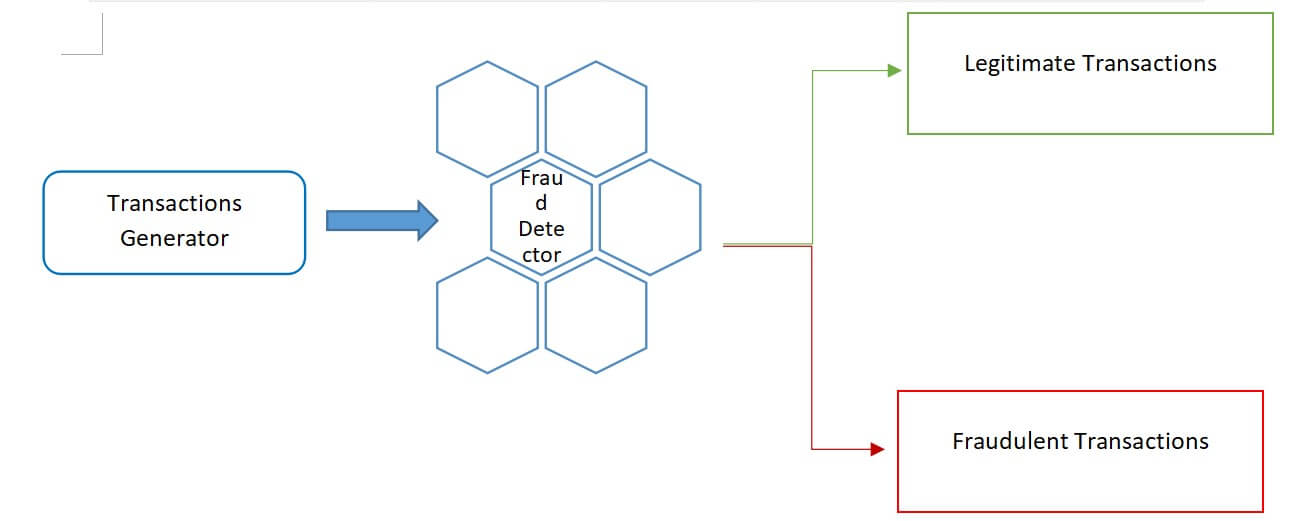
- A transactions generator, on one end, which produce fictitious transactions to simulate a flow of events.
- A fraud detector, on the other end, to filter out transactions which look suspicious.
The following process flowchart exhibits our design:
Let's jump right into the setup. Of course, you need Python 3 installed on your system. I will be using a virtual environment where I install the needed libraries and this is undoubtedly the best approach to opt for:
- Create a virtual environment and activate it:
$ python -m venv fraud-detector $ source fraud-detector/bin/activate - Create the file
requirements.txtand add the following lines to it:Kafka-python==2.0.2 Flask==1.1.2 - Install the libraries:
$ pip install -r requirements.txt
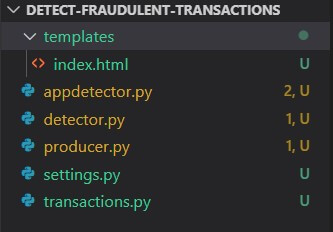
At the end of this tutorial, the folder structure will look like the following:
 With that cleared out, let's now start writing the actual code.
With that cleared out, let's now start writing the actual code.
First, let's initialize our parameters in our settings.py file:
# URL for our broker used for connecting to the Kafka cluster
KAFKA_BROKER_URL = "localhost:9092"
# name of the topic hosting the transactions to be processed and requiring processing
TRANSACTIONS_TOPIC = "queuing.transactions"
# these 2 variables will control the amount of transactions automatically generated
TRANSACTIONS_PER_SECOND = float("2.0")
SLEEP_TIME = 1 / TRANSACTIONS_PER_SECOND
# name of the topic hosting the legitimate transactions
LEGIT_TOPIC = "queuing.legit"
# name of the topic hosting the suspicious transactions
FRAUD_TOPIC = "queuing.fraud"Note: For the sake of brevity, I hardcoded the configuration parameters in settings.py, but it's recommended to store these parameters in a separate file (e.g .env)
Second, let's create a Python file called transactions.py for creating randomized transactions on the fly:
from random import choices, randint
from string import ascii_letters, digits
account_chars: str = digits + ascii_letters
def _random_account_id() -> str:
"""Return a random account number made of 12 characters"""
return "".join(choices(account_chars,k=12))
def _random_amount() -> float:
"""Return a random amount between 1.00 and 1000.00"""
return randint(100,1000000)/100
def create_random_transaction() -> dict:
"""Create a fake randomised transaction."""
return {
"source":_random_account_id()
,"target":_random_account_id()
,"amount":_random_amount()
,"currency":"EUR"
}Third, let's build our transactions generator which will use to create a stream of transactions. The Python file producer.py will play the role of the transactions generator and will store the published transactions within the topic called queuing.transactions, below is the code of producer.py:
import os
import json
from time import sleep
from kafka import KafkaProducer
# import initialization parameters
from settings import *
from transactions import create_random_transaction
if __name__ == "__main__":
producer = KafkaProducer(bootstrap_servers = KAFKA_BROKER_URL
#Encode all values as JSON
,value_serializer = lambda value: json.dumps(value).encode()
,)
while True:
transaction: dict = create_random_transaction()
producer.send(TRANSACTIONS_TOPIC, value= transaction)
print(transaction) #DEBUG
sleep(SLEEP_TIME)To make sure that you're on the right track, let's test the producer.py program. To do so, open up a terminal window and type the following:
$ python producer.pyNote: Make sure that Kafka server is running before executing the test.
You should see an output similar to the following:
 Fourth, after we guaranteed that our producer program is up and running, let's move now into building a fraud detection mechanism to process the stream of transactions and to pinpoint the fraudulent ones.
Fourth, after we guaranteed that our producer program is up and running, let's move now into building a fraud detection mechanism to process the stream of transactions and to pinpoint the fraudulent ones.
We will develop two versions of this program:
- Version 1
detector.py: This program will filter out the queued transactions based on a specific criteria or set of criteria and outputs the results into two separate topics: one for legitimate transactionsLEGIT_TOPICand the otherFRAUD_TOPICfor the fraudulent ones which do cater for the criteria we selected.
This program is based on Kafka Python consumer API, this API allows the consumers to subscribe to specific Kafka topics and Kafka will broadcast messages automatically to them as long as these messages are being published.
Below is the code for detector.py:
import os
import json
from kafka import KafkaConsumer, KafkaProducer
from settings import *
def is_suspicious(transaction: dict) -> bool:
"""Simple condition to determine whether a transaction is suspicious."""
return transaction["amount"] >= 900
if __name__ == "__main__":
consumer = KafkaConsumer(
TRANSACTIONS_TOPIC
,bootstrap_servers=KAFKA_BROKER_URL
,value_deserializer = lambda value: json.loads(value)
,
)
for message in consumer:
transaction: dict = message.value
topic = FRAUD_TOPIC if is_suspicious(transaction) else LEGIT_TOPIC
print(topic,transaction) #DEBUGFor simplicity, I selected a basic condition is_suspicious() function that is based on a simple predicate (that is, if the transaction amount is greater than or equals 900, then it is suspicious). However, in real life scenarios, many parameters might be involved, among which:
- The initiator account for the transaction whether active, inactive or dormant.
- The location of the transaction if initiated from an entity supposedly closed during a lockdown period.
These scenarios will constitute the core of a fraud management solution and should be carefully designed to ensure the flexibility and the responsiveness of this solution.
Let's now test both producer.py and detector.py, open up a new terminal window and type the following:
$ python producer.pyConcurrently, open up another window and type:
$ python detector.pyNote: Make sure that Kafka server is running before executing the test.
You'll see a similar output to this on detector.py:
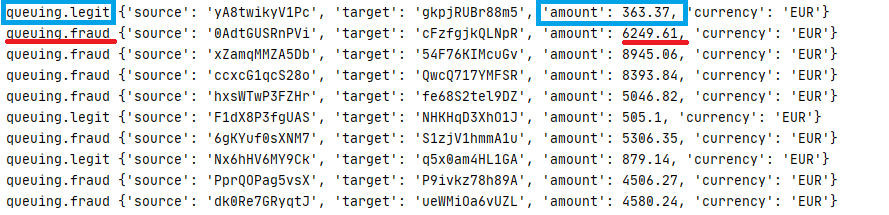 The debug print included within the program will output the transactions to the console and will indicate the target queue based on the condition we specified and related the amount of the transaction.
The debug print included within the program will output the transactions to the console and will indicate the target queue based on the condition we specified and related the amount of the transaction.
- Version 2
appdetector.py: This is an advanced version of the detector.py script, which will enable the streaming of the transactions to the web using Flask micro framework.
Technologies used in this code are the following:
- Flask: a micro web framework in Python.
- Server-Sent events (SSE): a type of server push mechanism, where a client subscribes to a stream of updates, generated by a server, and whenever a new event occurs, a notification is sent to the client.
- Jinja2: a modern template engine widely used in the Python ecosystem. Flask supports Jinja2 by default.
Below is appdetector.py:
from flask import Flask, Response, stream_with_context, render_template, json, url_for
from kafka import KafkaConsumer
from settings import *
# create the flask object app
app = Flask(__name__)
def stream_template(template_name, **context):
print('template name =',template_name)
app.update_template_context(context)
t = app.jinja_env.get_template(template_name)
rv = t.stream(context)
rv.enable_buffering(5)
return rv
def is_suspicious(transaction: dict) -> bool:
"""Determine whether a transaction is suspicious."""
return transaction["amount"] >= 900
# this router will render the template named index.html and will pass the following parameters to it:
# title and Kafka stream
@app.route('/')
def index():
def g():
consumer = KafkaConsumer(
TRANSACTIONS_TOPIC
, bootstrap_servers=KAFKA_BROKER_URL
, value_deserializer=lambda value: json.loads(value)
,
)
for message in consumer:
transaction: dict = message.value
topic = FRAUD_TOPIC if is_suspicious(transaction) else LEGIT_TOPIC
print(topic, transaction) # DEBUG
yield topic, transaction
return Response(stream_template('index.html', title='Fraud Detector / Kafka',data=g()))
if __name__ == "__main__":
app.run(host="localhost" , debug=True)Next, we'll define the template index.html HTML file that was used by index() route function and is under templates folder:
<!doctype html>
<title> Send Javascript with template demo </title>
<html>
<head>
</head>
<body>
<div class="container">
<h1>{{title}}</h1>
</div>
<div id="data"></div>
{% for topic, transaction in data: %}
<script>
var topic = "{{ topic }}";
var transaction = "{{ transaction }}";
if (topic.search("fraud") > 0) {
topic = topic.fontcolor("red")
} else {
topic = topic.fontcolor("green")
}
document.getElementById('data').innerHTML += "<br>" + topic + " " + transaction;
</script>
{% endfor %}
</body>
</html>The index.html contains a Javascript enabling to iterate throughout the received stream and to display the transactions as they're received.
Now to run it, make sure producer.py is running, and then:
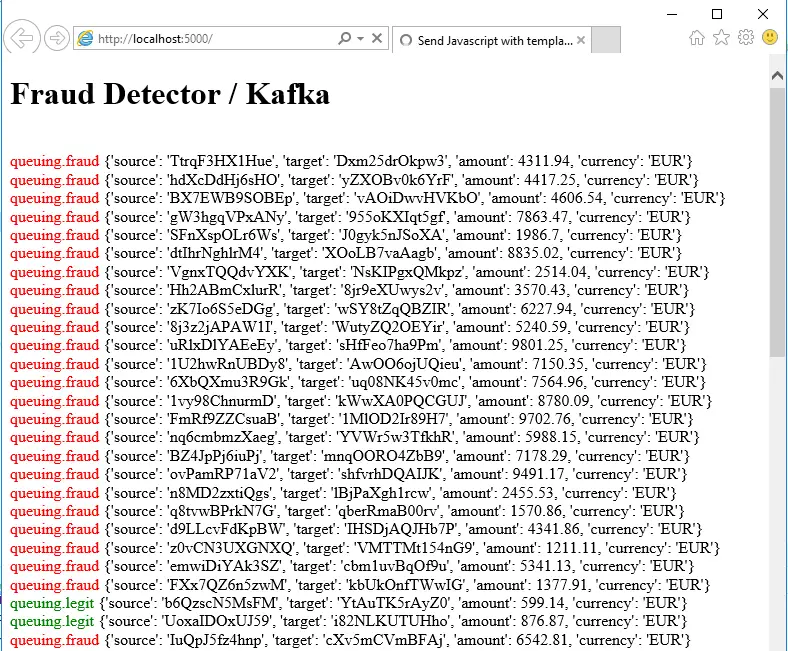
$ python appdetector.pyIt should start a local server on port 5000, go to your browser and access http://localhost:5000 where the Flask instance is running, you'll see a continuous streaming of legitimate and fraudulent transactions as shown in the following screen:
 You can check the full code here.
You can check the full code here.
This tutorial has illustrated how you can apply the stream processing paradigm in fraud detection applications.
Learn also: Recommender Systems using Association Rules Mining in Python.
Happy coding ♥
Take the stress out of learning Python. Meet our Python Code Assistant – your new coding buddy. Give it a whirl!
View Full Code Auto-Generate My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!