Welcome! Meet our Python Code Assistant, your new coding buddy. Why wait? Start exploring now!
BLEU stands for "Bilingual Evaluation Understudy". It is a metric commonly used in natural language processing (NLP) for evaluating:
- Machine-generated sentences to reference sentences.
- In text summarization, BLEU can assess the similarity between generated summaries and human-written references.
- In image captioning, BLEU can evaluate the quality of automatically generated captions.
- In paraphrasing tasks, BLEU can measure the similarity between a generated paraphrase and the original sentence.
Let's explain the BLEU score in simple terms:
Imagine you have a machine translation system that translates sentences from one language to another. Now, if you want to know how good the translations are, then the BLEU score is a way to measure the quality of these translations.
The BLEU score is based on a simple idea, comparing the machine-generated translations with human-generated translations that are considered correct.
Here's how it works:
- The machine translation system generates translations for a set of sentences.
- These machine-generated translations are compared to the reference translations.
- The comparison is done by counting how many words or phrases from the machine-generated translations match the words or phrases in the reference translations.
- The more matches there are, the higher the BLEU score will be.
The BLEU score considers the precision of matching words or phrases. It also considers the length of the translations to avoid favoring shorter translations that may have an advantage in matching words by chance.
The BLEU score is typically represented as a value between 0 and 1, with 1 being a perfect match and 0 being a perfect mismatch to the reference translations.
Table of contents:
- How to Calculate the BLEU Score
- Calculate the BLEU Score using n-grams
- Calculate the BLEU score using the NLTK Library
- Conclusion
How to Calculate the BLEU Score
Before proceeding to the BLEU score calculation, let's briefly look at n-grams.
Let’s say you have a sentence: "I love to eat ice cream." An n-gram is just a fancy way of saying "a group of words." The n in n-gram represents the number of words in that group.
For example:
- A unigram (n=1) would be a single word: "I," "love," "to," "eat," "ice," or "cream."
- A bigram (n=2) would be a group of two words: "I love," "love to," "to eat," "eat ice," or "ice cream."
- A trigram (n=3) would be a group of three words: "I love to," "love to eat," "to eat ice," and "eat ice cream."
N-grams help us understand patterns and relationships between words in a sentence or a text. They can be used to predict what word might come next, to generate new text, or to analyze the frequency of certain word combinations.
For example, if we use bigrams, we can see that "I love" is a common phrase, and "to eat" is another common phrase in the sentence "I love to eat ice cream." By studying these n-grams, computers can learn about language and generate more natural-sounding sentences or make predictions based on the patterns they find.
Calculate the BLEU Score using n-grams
Let's explain the calculation of the BLEU score using n-grams.
Calculate the n-gram Precision
N-gram precision measures how well the candidate sentence matches the reference sentences in terms of n-gram sequences. It considers the count of matching n-grams in the candidate sentence and the maximum count of those n-grams in the reference sentences.
The formula to calculate precision for a particular n-gram size is:
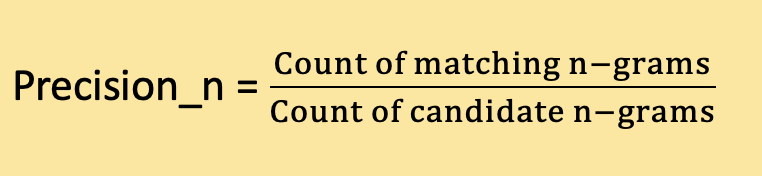
Calculate the Brevity Penalty
The brevity penalty addresses the issue of shorter candidate sentences receiving higher scores. It penalizes the BLEU score if the candidate sentence is significantly shorter than the reference sentences.
The brevity penalty is calculated as:

Calculate the n-gram Weights
N-gram weights assign different levels of importance to different n-gram sizes. Typically, equal weights are assigned to each n-gram size. For example, for 2-gram, the weights can be (0.5, 0.5), and for 3-gram, the weights can be (0.33, 0.33, 0.33).
Calculation of the Final BLEU Score
The BLEU score combines the n-gram precisions with the brevity penalty to get the final score. The precisions are weighted by their respective weights, and the brevity penalty is applied:
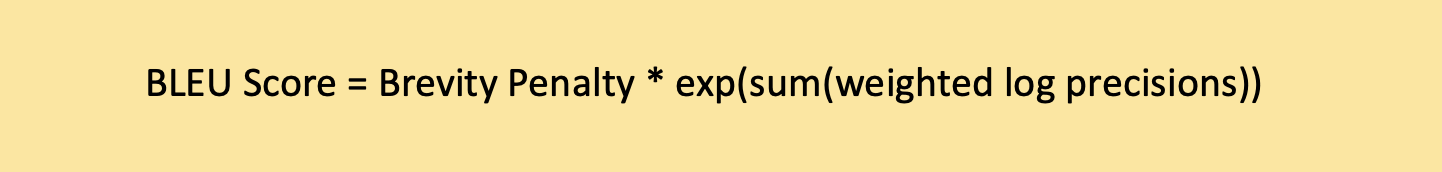
Calculate the BLEU Score using the NLTK library
Now to calculate the BLEU score in Python, we will use the NLTK library. NLTK stands for "natural language toolkit," which is widely used in the field of NLP. Let's install it:
$ pip install nltkImport the Necessary Modules
Import the sentence_bleu() function from the nltk.translate.bleu_score module:
from nltk.translate.bleu_score import sentence_bleu, corpus_bleuPrepare the Reference Sentences
A reference sentence is a human-generated sentence. Create a list of reference sentences and split them into individual words or tokens:
# Prepare the reference sentences
reference1 = ['I', 'love', 'eating', 'ice', 'cream']
reference2 = ['I', 'enjoy', 'eating', 'ice', 'cream']
Prepare the Candidate Sentence
A candidate sentence is a machine-generated sentence, but for this tutorial, we'll just hand-craft it:
# Prepare the candidate sentence
translation = ['I', 'love', 'eating', 'ice', 'cream']
Calculate the BLEU Score
Use the sentence_bleu() function and pass the list of reference sentences and the candidate sentence tokens as arguments. The function calculates the BLEU score, which indicates the similarity between the candidate and reference sentences:
# Calculate the BLEU score for a single sentence
bleu_score = sentence_bleu([reference1, reference2], translation)
print("BLEU Score: ", bleu_score)
Output:
BLEU Score: 1.0# Prepare the reference sentences and candidate sentences for multiple translations
references = [['I', 'love', 'eating', 'ice', 'cream'], ['He', 'enjoys', 'eating', 'cake']]
translations = [['I', 'love', 'eating', 'ice', 'cream'], ['He', 'likes', 'to', 'eat', 'cake']]
# Create a list of reference lists
references_list = [[ref] for ref in references]
# Calculate BLEU score for the entire corpus
bleu_score_corpus = corpus_bleu(references_list, translations)
print("Corpus BLEU Score: ", bleu_score_corpus)
Output:
Corpus BLEU Score: 0.5438786529686386The sentence_bleu() function in NLTK calculates the BLEU score for a single candidate sentence compared to one or more reference sentences. On the other hand, the corpus_bleu() function calculates the BLEU score for multiple candidate sentences and their respective reference sentences in a corpus (large collection of text or linguistic data). While sentence_bleu() focuses on individual sentences and provides an average score, corpus_bleu() takes into account all the sentences in the corpus and provides a single score that represents the overall quality of translations in the corpus.
Conclusion
The BLEU score tells you how similar machine-generated translations are to human-generated translations. It gives you a way to measure the quality of the machine translation system by comparing it to the desired or reference translations.
I hope this tutorial was beneficial for you in your NLP journey!
Here are some tutorials where we used the BLEU score:
- How to Perform Text Summarization using Transformers in Python
- Image Captioning using PyTorch and Transformers in Python
- Machine Translation using Transformers in Python
Get the complete code here.
Happy learning ♥
Let our Code Converter simplify your multi-language projects. It's like having a coding translator at your fingertips. Don't miss out!
View Full Code Auto-Generate My Code


Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!