Step up your coding game with AI-powered Code Explainer. Get insights like never before!
At these times, companies of mid and large-scale have large amounts of PDF documents being used daily. Among them are invoices, receipts, documents, reports, and more.
In this tutorial, you will learn how you can extract text from PDF documents in Python using the PyMuPDF library.
This tutorial tackles the problem when the text isn't scanned, i.e., not an image within a PDF. If you want to extract text from images in PDF documents, this tutorial is for you.
Download: Practical Python PDF Processing EBook.
To get started, we need to install PyMuPDF:
$ pip install PyMuPDF==1.18.9Open up a new Python file, and let's import the libraries:
import fitz
import argparse
import sys
import os
from pprint import pprintPyMuPDF has the name of fitz when importing in Python, so keep that in mind.
Since we're going to make a Python script that extracts text from PDF documents, we have to use the argparse module to parse the passed parameters in the command line. The following function parses the arguments and does some processing:
def get_arguments():
parser = argparse.ArgumentParser(
description="A Python script to extract text from PDF documents.")
parser.add_argument("file", help="Input PDF file")
parser.add_argument("-p", "--pages", nargs="*", type=int,
help="The pages to extract, default is all")
parser.add_argument("-o", "--output-file", default=sys.stdout,
help="Output file to write text. default is standard output")
parser.add_argument("-b", "--by-page", action="store_true",
help="Whether to output text by page. If not specified, all text is joined and will be written together")
# parse the arguments from the command-line
args = parser.parse_args()
input_file = args.file
pages = args.pages
by_page = args.by_page
output_file = args.output_file
# print the arguments, just for logging purposes
pprint(vars(args))
# load the pdf file
pdf = fitz.open(input_file)
if not pages:
# if pages is not set, default is all pages of the input PDF document
pages = list(range(pdf.pageCount))
# we make our dictionary that maps each pdf page to its corresponding file
# based on passed arguments
if by_page:
if output_file is not sys.stdout:
# if by_page and output_file are set, open all those files
file_name, ext = os.path.splitext(output_file)
output_files = { pn: open(f"{file_name}-{pn}{ext}", "w") for pn in pages }
else:
# if output file is standard output, do not open
output_files = { pn: output_file for pn in pages }
else:
if output_file is not sys.stdout:
# a single file, open it
output_file = open(output_file, "w")
output_files = { pn: output_file for pn in pages }
else:
# if output file is standard output, do not open
output_files = { pn: output_file for pn in pages }
# return the parsed and processed arguments
return {
"pdf": pdf,
"output_files": output_files,
"pages": pages,
}First, we made our parser using ArgumentParserAnd add the following parameters:
file: The input PDF document to extract text from.-por--pages: The page indices to extract, starting from 0, if you do not specify, the default will be all pages.-oor--output-file: The output text file to write the extracted text. If you do not specify, the content will be printed in the standard output (i.e., in the console).-bor--by-page: This is a boolean indicating whether to output text by page. If not specified, all text is joined in a single file (when-ois specified).
Second, we open our output_files to write into if -b is specified. Otherwise, a single file will be in the output_files dictionary.
Finally, we return the necessary variables: PDF document, output files, and the list of page numbers.
Next, let's make a function that accepts the above parameters and extract text from PDF documents accordingly:
def extract_text(**kwargs):
# extract the arguments
pdf = kwargs.get("pdf")
output_files = kwargs.get("output_files")
pages = kwargs.get("pages")
# iterate over pages
for pg in range(pdf.pageCount):
if pg in pages:
# get the page object
page = pdf[pg]
# extract the text of that page and split by new lines '\n'
page_lines = page.get_text().splitlines()
# get the output file
file = output_files[pg]
# get the number of lines
n_lines = len(page_lines)
for line in page_lines:
# remove any whitespaces in the end & beginning of the line
line = line.strip()
# print the line to the file/stdout
print(line, file=file)
print(f"[*] Wrote {n_lines} lines in page {pg}")
# close the files
for pn, f in output_files.items():
if f is not sys.stdout:
f.close()Get Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookWe iterate over the pages; if the page we're on is in the pages list, we extract the text of that page and write it to the specified file or standard output. Finally, we close the files.
Let's bring everything together and run the functions:
if __name__ == "__main__":
# get the arguments
kwargs = get_arguments()
# extract text from the pdf document
extract_text(**kwargs)Awesome, let's try to extract the text from all pages of this file and write each page to a text file:
$ python extract_text_from_pdf.py bert-paper.pdf -o text.txt -bOutput:
{'by_page': True,
'file': 'bert-paper.pdf',
'output_file': 'text.txt',
'pages': None}
[*] Wrote 97 lines in page 0
[*] Wrote 108 lines in page 1
[*] Wrote 136 lines in page 2
[*] Wrote 107 lines in page 3
[*] Wrote 133 lines in page 4
[*] Wrote 158 lines in page 5
[*] Wrote 163 lines in page 6
[*] Wrote 128 lines in page 7
[*] Wrote 158 lines in page 8
[*] Wrote 116 lines in page 9
[*] Wrote 124 lines in page 10
[*] Wrote 115 lines in page 11
[*] Wrote 135 lines in page 12
[*] Wrote 111 lines in page 13
[*] Wrote 153 lines in page 14
[*] Wrote 127 lines in page 15It worked perfectly. Here are the output files:
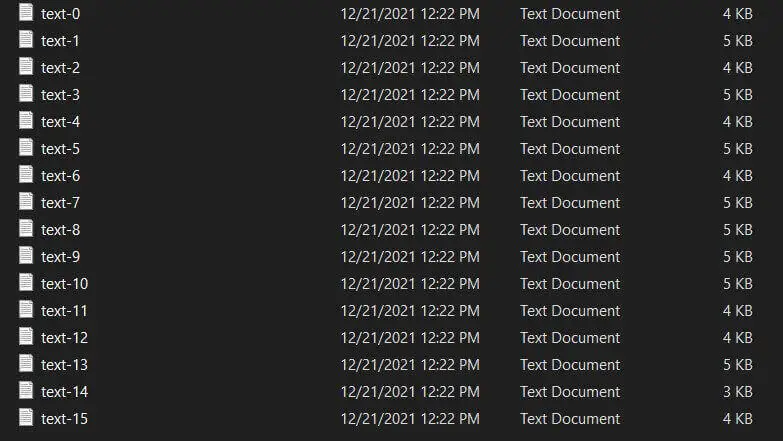 Now let's specify pages 0, 1, 2, 14, and 15:
Now let's specify pages 0, 1, 2, 14, and 15:
$ python extract_text_from_pdf.py bert-paper.pdf -o text.txt -b -p 0 1 2 14 15
{'by_page': True,
'file': 'bert-paper.pdf',
'output_file': 'text.txt',
'pages': [0, 1, 2, 14, 15]}
[*] Wrote 97 lines in page 0
[*] Wrote 108 lines in page 1
[*] Wrote 136 lines in page 2
[*] Wrote 153 lines in page 14
[*] Wrote 127 lines in page 15We can also print in the console instead of saving it to a file by not setting the -o option:
$ python extract_text_from_pdf.py bert-paper.pdf -p 0
{'by_page': False,
'file': 'bert-paper.pdf',
'output_file': <_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>,
'pages': [0]}
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Jacob Devlin
Ming-Wei Chang
Kenton Lee
Kristina Toutanova
Google AI Language
{jacobdevlin,mingweichang,kentonl,kristout}@google.com
Abstract
We introduce a new language representa-
tion model called BERT, which stands for
Bidirectional Encoder Representations from
...
<SNIPPED>
[*] Wrote 97 lines in page 0Or saving all the text of the PDF document into a single text file:
$ python extract_text_from_pdf.py bert-paper.pdf -o all-text.txtThe output file will appear in the current directory:
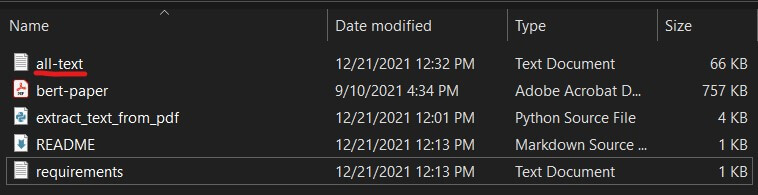 Conclusion
Conclusion
Alright, that's it for this tutorial. As mentioned earlier, you can always extract text from scanned PDF documents tutorial if your documents are scanned (i.e., as images and cannot be selected in your PDF reader).
Also, you can redact and highlight the text in your PDF. Below are some other related PDF tutorials:
- How to Extract Tables from PDF in Python
- How to Encrypt and Decrypt PDF Files in Python
- How to Sign PDF Files in Python
- How to Split PDF Files in Python
- How to Extract All PDF Links in Python
Or you can explore all of them here.
Check the complete code here.
Finally, unlock the secrets of Python PDF manipulation! Our compelling Practical Python PDF Processing eBook offers exclusive, in-depth guidance you won't find anywhere else. If you're passionate about enriching your skill set and mastering the intricacies of PDF handling with Python, your journey begins with a single click right here. Let's explore together!
Happy coding ♥
Ready for more? Dive deeper into coding with our AI-powered Code Explainer. Don't miss it!
View Full Code Improve My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!