Struggling with multiple programming languages? No worries. Our Code Converter has got you covered. Give it a go!
In this tutorial, you’ll learn how to search for usernames across multiple social media websites using Python. This is a form of OSINT (Open Source Intelligence). There is an available tool that does this - Sherlock. But in this tutorial, we’ll learn how to build ours in Python because we’re programmers, and we’re cool.
This program is designed to check if a given username exists on various popular websites, such as Instagram, Facebook, YouTube, Reddit, GitHub, etc. It automates the tedious process of manually checking for a user's presence across multiple platforms, saving time and effort.
This is possible because most social media profiles are accessible via URLs. For example, on your search bar, if you type in instagram.com/cristiano, you’ll land on Cristiano Ronaldo’s Instagram page. It’s the same for many other websites. This is how we’ll achieve that.
I know you may be thinking that checking the result of a simple request.get() would suffice, but that’s not entirely the case for a sophisticated program. You will encounter more limitations by doing just that. We’ll make our program more sophisticated by utilizing Python's concurrent.futures module. This program can check multiple websites concurrently, significantly improving performance and reducing the overall execution time.
Related: How to Automate Login using Selenium in Python.
To get started, install colorama for colored output:
$ pip install coloramaLet’s get coding. Open up a new Python file, name it meaningfully like username_finder.py and follow along. As usual, we start by importing the necessary libraries:
# Import necessary libraries
import requests # For making HTTP requests
import argparse # For parsing command line arguments
import concurrent.futures # For concurrent execution
from collections import OrderedDict # For maintaining order of websites
from colorama import init, Fore # For colored terminal output
import time # For handling time-related tasks
import random # For generating random numbersNext, we initialize colorama and create a dictionary specifying our desired websites. We’ll use only nine websites for demonstration, but feel free to use as many as you like:
# Initialize colorama for colored output.
init()
# Ordered dictionary of websites to check for a given username.
WEBSITES = OrderedDict([
("Instagram", "https://www.instagram.com/{}"),
("Facebook", "https://www.facebook.com/{}"),
("YouTube", "https://www.youtube.com/user/{}"),
("Reddit", "https://www.reddit.com/user/{}"),
("GitHub", "https://github.com/{}"),
("Twitch", "https://www.twitch.tv/{}"),
("Pinterest", "https://www.pinterest.com/{}/"),
("TikTok", "https://www.tiktok.com/@{}"),
("Flickr", "https://www.flickr.com/photos/{}")
])Next, we define parameters to implement rate limiting and retry mechanisms to improve consistency:
REQUEST_DELAY = 2 # Delay in seconds between requests to the same website
MAX_RETRIES = 3 # Maximum number of retries for a failed request
last_request_times = {} # Dictionary to track the last request time for each websiteNext, we define a function that does the main thing - check if the username exists:
def check_username(website, username):
"""
Check if the username exists on the given website.
Returns the full URL if the username exists, False otherwise.
"""
url = website.format(username) # Format the URL with the given username
retries = 0 # Initialize retry counter
# Retry loop
while retries < MAX_RETRIES:
try:
# Implement rate limiting.
current_time = time.time()
if website in last_request_times and current_time - last_request_times[website] < REQUEST_DELAY:
delay = REQUEST_DELAY - (current_time - last_request_times[website])
time.sleep(delay) # Sleep to maintain the request delay.
response = requests.get(url) # Make the HTTP request
last_request_times[website] = time.time() # Update the last request time.
if response.status_code == 200: # Check if the request was successful.
return url
else:
return False
except requests.exceptions.RequestException:
retries += 1 # Increment retry counter on exception.
delay = random.uniform(1, 3) # Random delay between retries.
time.sleep(delay) # Sleep for the delay period.
return False # Return False if all retries failed.This function check_username() takes a website URL template and a username as input, and does the following:
- Constructs the full URL by formatting the template with the username.
- Implements a rate-limiting mechanism by checking if the time since the last request to the same website is less than
REQUEST_DELAY. If so, it sleeps for the remaining time before making the next request. - Sends a GET request to the constructed URL using the
requests.get()method. - Updates the
last_request_timesdictionary with the current time for the website. - If the response status code is 200 (OK), it returns the URL, indicating that the username exists on that website.
- If the response status code is not 200, it returns
False, indicating that the username does not exist. - If a
RequestExceptionoccurs (e.g., network error, timeout), it continues to the next iteration of the loop and retries the request up toMAX_RETRIEStimes, introducing a random delay between 1 and 3 seconds before each retry. - If all retries fail, it returns
False.
Finally, we define a main() function to handle the user argument using argparse and implement concurrent searching for faster results:
def main():
# Parse command line arguments.
parser = argparse.ArgumentParser(description="Check if a username exists on various websites.")
parser.add_argument("username", help="The username to check.")
parser.add_argument("-o", "--output", help="Path to save the results to a file.")
args = parser.parse_args()
username = args.username # Username to check.
output_file = args.output # Output file path.
print(f"Checking for username: {username}")
results = OrderedDict() # Dictionary to store results.
# Use ThreadPoolExecutor for concurrent execution.
with concurrent.futures.ThreadPoolExecutor() as executor:
# Submit tasks to the executor.
futures = {executor.submit(check_username, website, username): website_name for website_name, website in WEBSITES.items()}
for future in concurrent.futures.as_completed(futures):
website_name = futures[future] # Get the website name.
try:
result = future.result() # Get the result.
except Exception as exc:
print(f"{website_name} generated an exception: {exc}")
result = False
finally:
results[website_name] = result # Store the result.
# Print the results.
print("\nResults:")
for website, result in results.items():
if result:
print(f"{Fore.GREEN}{website}: Found ({result})")
else:
print(f"{Fore.RED}{website}: Not Found")
# Save results to a file if specified.
if output_file:
with open(output_file, "w") as f:
for website, result in results.items():
if result:
f.write(f"{website}: Found ({result})\n")
else:
f.write(f"{website}: Not Found\n")
print(f"{Fore.GREEN}\nResults saved to {output_file}")
# Call the main function
main()The main() function performs the following steps:
- Parses the command-line arguments using the
argparsemodule, allowing the user to provide a username and an optional output file path. - Prints the username being checked.
- Creates an empty
OrderedDictto store the results. - Uses a
ThreadPoolExecutorfrom theconcurrent.futuresmodule to execute thecheck_username()function concurrently for each website in theWEBSITESlist. - As the futures (tasks) complete, it collects the results in the
resultsdictionary. - Prints the results to the console, displaying whether the username was found or not on each website, using colored output (green for found, red for not found).
- If an output file path is provided, it writes the results to the specified file.
And that’s it. To run the program:
$ python username_finder.py cristiano -o usernames.txtMy results:
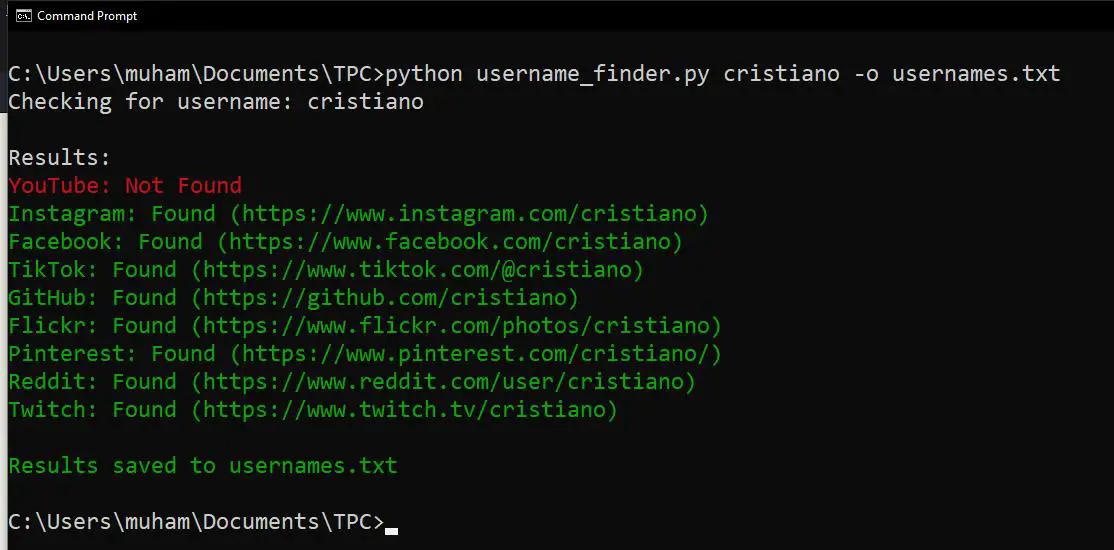
The text file will be saved in your working directory. We’re done with the program!
Please note that while the program attempts to accurately detect the existence of usernames on various websites by implementing rate limiting and retry mechanisms to improve consistency, its accuracy and consistency may be limited by factors such as website structure changes, anti-scraping measures, and dynamic content rendering. Some websites may employ advanced techniques to prevent automated username checking, which could lead to false negatives or false positives. These factors are beyond us as programmers. Regardless, this program still does a very decent job while it's relatively simple.
Also, web scraping and automated username checking may violate the terms of service of some websites. You should use this program responsibly and within legal and ethical boundaries. Excessive or abusive usage could potentially lead to IP bans or legal consequences.
You can find the complete code here.
Learn also: How to Build a Twitter (X) Bot in Python
Till next time, cheers!
Take the stress out of learning Python. Meet our Python Code Assistant – your new coding buddy. Give it a whirl!
View Full Code Create Code for Me




Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!