Step up your coding game with AI-powered Code Explainer. Get insights like never before!
In this tutorial, we will demonstrate how to extract images from PDF files and save them on the local disk using Python, along with the PyMuPDF and Pillow libraries.
PyMuPDF is a versatile library that allows you to access PDF, XPS, OpenXPS, epub, and various other file extensions, while Pillow is an open-source Python imaging library that adds image processing capabilities to your Python interpreter.
To follow along with this tutorial, you will need:
- Python 3.x installed on your system
- A PDF file containing images you want to extract
Download: Practical Python PDF Processing EBook.
Installing PyMuPDF and Pillow Libraries
First, we need to install the PyMuPDF and Pillow libraries. Open your terminal or command prompt and run the following command:
pip3 install PyMuPDF PillowImporting the Libraries and Setting Up Options
Create a new Python file named pdf_image_extractor.py and import the necessary libraries. Also, define the output directory, output image format, and minimum dimensions for the extracted images:
import os
import fitz # PyMuPDF
import io
from PIL import Image
# Output directory for the extracted images
output_dir = "extracted_images"
# Desired output image format
output_format = "png"
# Minimum width and height for extracted images
min_width = 100
min_height = 100
# Create the output directory if it does not exist
if not os.path.exists(output_dir):
os.makedirs(output_dir)Get Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookLoading the PDF File
I'm gonna test this with this PDF file, but you're free to bring and PDF file and put it in your current working directory, let's load it to the library:
# file path you want to extract images from
file = "1710.05006.pdf"
# open the file
pdf_file = fitz.open(file)Iterating Over Pages and Extracting Images
Since we want to extract images from all pages, we need to iterate over all the pages available and get all image objects on each page, the following code does that:
# Iterate over PDF pages
for page_index in range(len(pdf_file)):
# Get the page itself
page = pdf_file[page_index]
# Get image list
image_list = page.get_images(full=True)
# Print the number of images found on this page
if image_list:
print(f"[+] Found a total of {len(image_list)} images in page {page_index}")
else:
print(f"[!] No images found on page {page_index}")
# Iterate over the images on the page
for image_index, img in enumerate(image_list, start=1):
# Get the XREF of the image
xref = img[0]
# Extract the image bytes
base_image = pdf_file.extract_image(xref)
image_bytes = base_image["image"]
# Get the image extension
image_ext = base_image["ext"]
# Load it to PIL
image = Image.open(io.BytesIO(image_bytes))
# Check if the image meets the minimum dimensions and save it
if image.width >= min_width and image.height >= min_height:
image.save(
open(os.path.join(output_dir, f"image{page_index + 1}_{image_index}.{output_format}"), "wb"),
format=output_format.upper())
else:
print(f"[-] Skipping image {image_index} on page {page_index} due to its small size.")
Related: How to Convert PDF to Images in Python.
In this code snippet, we use the get_images(full=True) method to list all available image objects on a particular page. Then, we loop through the images, check if they meet the minimum dimensions, and save them using the specified output format in the output directory.
We use the extract_image() method that returns the image in bytes and additional information, such as the image extension.
So, we convert the image bytes to a PIL image instance and save it to the local disk using the save() method which accepts a file pointer as an argument; we're simply naming the images with their corresponding page and image indices.
Running the Script and Verifying the Output
Now, save the script and run it using the following command:
$ python pdf_image_extractor.py
I got the following output:
[!] No images found on page 0
[+] Found a total of 3 images in page 1
[+] Found a total of 3 images in page 2
[!] No images found on page 3
[!] No images found on page 4The extracted images that meet the minimum dimensions will be saved in the specified output directory with their corresponding page and image indices, using the desired output format.
The images are saved in the extracted_images folder, as specified:
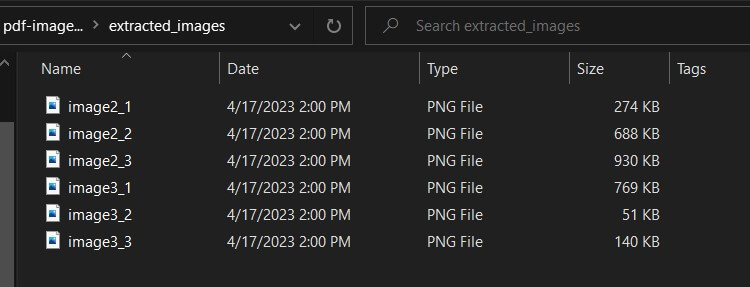 Conclusion
Conclusion
In this tutorial, we have successfully demonstrated how to extract images from PDF files using Python, PyMuPDF, and Pillow libraries. This technique can be extended to work with various file formats and customized to fit your specific requirements.
For more information on how the libraries work, refer to the official documentation:
I have used the argparse module to create a quick CLI script, you can get both versions of the code here.
Here are some PDF Related tutorials:
- How to Convert HTML to PDF in Python
- How to Extract All PDF Links in Python.
- How to Extract PDF Tables in Python.
- How to Extract Text from PDF in Python.
Finally, for more PDF handling guides on Python, you can check our Practical Python PDF Processing EBook, where we dive deeper into PDF document manipulation with Python, make sure to check it out here if you're interested!
Happy coding ♥
Finished reading? Keep the learning going with our AI-powered Code Explainer. Try it now!
View Full Code Improve My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!