Before we get started, have you tried our new Python Code Assistant? It's like having an expert coder at your fingertips. Check it out!
Speech Recognition is the technology that allows to transform human speech into digital text. In this tutorial, you will learn how to perform automatic speech recognition with Python.
This is a hands-on guide, you will learn to use the following:
- SpeechRecognition library: This library contains several engines and APIs, both online and offline. We will use Google Speech Recognition, as it's faster to get started and doesn't require any API key. We have a separate tutorial on this.
- The Whisper API: Whisper is a robust general-purpose speech recognition model released by OpenAI. The API was made available on the 1st of March 2023. We will use the OpenAI API to perform speech recognition.
- Perform inference directly on Whisper models: Whisper is open-source. Therefore, we can directly use our computing resources to perform ASR. We will have the flexibility and the choice of which size of the whisper model to use. We also have a separate tutorial for using the Transformers library with Whisper along with Wav2Vec2.
Table of Content
With SpeechRecognition Library
In this section, we will base our speech recognition system on this tutorial. SpeechRecognition library offers many transcribing engines like Google Speech Recognition, and that's what we'll be using.
Before we get started, let's install the required libraries:
$ pip install SpeechRecognition pydubOpen up a new file named speechrecognition.py, and add the following:
# importing libraries
import speech_recognition as sr
import os
from pydub import AudioSegment
from pydub.silence import split_on_silence
# create a speech recognition object
r = sr.Recognizer()The below function loads the audio file, performs speech recognition, and returns the text:
# a function to recognize speech in the audio file
# so that we don't repeat ourselves in in other functions
def transcribe_audio(path):
# use the audio file as the audio source
with sr.AudioFile(path) as source:
audio_listened = r.record(source)
# try converting it to text
text = r.recognize_google(audio_listened)
return textNext, we make a function to split the audio files into chunks in silence:
# a function that splits the audio file into chunks on silence
# and applies speech recognition
def get_large_audio_transcription_on_silence(path):
"""
Splitting the large audio file into chunks
and apply speech recognition on each of these chunks
"""
# open the audio file using pydub
sound = AudioSegment.from_file(path)
# split audio sound where silence is 700 miliseconds or more and get chunks
chunks = split_on_silence(sound,
# experiment with this value for your target audio file
min_silence_len = 500,
# adjust this per requirement
silence_thresh = sound.dBFS-14,
# keep the silence for 1 second, adjustable as well
keep_silence=500,
)
folder_name = "audio-chunks"
# create a directory to store the audio chunks
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
whole_text = ""
# process each chunk
for i, audio_chunk in enumerate(chunks, start=1):
# export audio chunk and save it in
# the `folder_name` directory.
chunk_filename = os.path.join(folder_name, f"chunk{i}.wav")
audio_chunk.export(chunk_filename, format="wav")
# recognize the chunk
with sr.AudioFile(chunk_filename) as source:
audio_listened = r.record(source)
# try converting it to text
try:
text = r.recognize_google(audio_listened)
except sr.UnknownValueError as e:
print("Error:", str(e))
else:
text = f"{text.capitalize()}. "
print(chunk_filename, ":", text)
whole_text += text
# return the text for all chunks detected
return whole_textLet's give it a try:
print(get_large_audio_transcription_on_silence("7601-291468-0006.wav"))Note: You can get all the tutorial files here.
Output:
audio-chunks\chunk1.wav : His abode which you had fixed in a bowery or country seat.
audio-chunks\chunk2.wav : Have a short distance from the city.
audio-chunks\chunk3.wav : Just at what is now called dutch street.
audio-chunks\chunk4.wav : Soon abounded with proofs of his ingenuity.
audio-chunks\chunk5.wav : Patent smokejack.
audio-chunks\chunk6.wav : It required a horse to work some.
audio-chunks\chunk7.wav : Dutch oven roasted meat without fire.
audio-chunks\chunk8.wav : Carts that went before the horses.
audio-chunks\chunk9.wav : Weather cox that turned against the wind and other wrongheaded contrivances.
audio-chunks\chunk10.wav : So just understand confound it all beholders.
His abode which you had fixed in a bowery or country seat. Have a short distance from the city. Just at what is now called dutch street. Soon abounded with proofs of his ingenuity. Patent smokejack. It required a horse to work some. Dutch oven roasted meat without fire. Carts that went before the horses. Weather cox that turned against the wind and other wrongheaded contrivances. So just understand confound it all beholders.Related: How to Convert Text to Speech in Python.
Using the Whisper API
If you want a more reliable API, I suggest you use OpenAI's Whisper API. To get started, you have to sign up for an OpenAI account here.
Once you have your account, go to the API keys page, and create an API key:
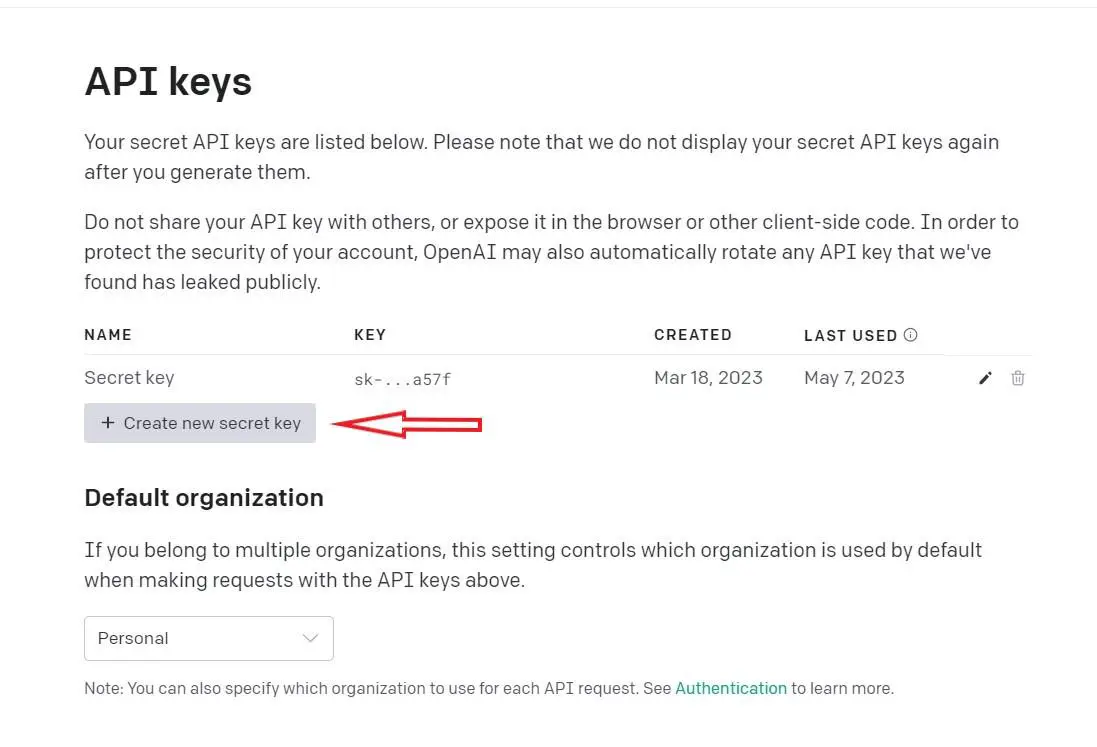 Once you've done that, install the
Once you've done that, install the openai library for Python:
$ pip install openaiNow copy the API key to a new Python file, named whisper_api.py:
import openai
# API key
openai.api_key = "<API_KEY>"Put your API key there, and add the following code:
def get_openai_api_transcription(audio_filename):
# open the audio file
with open(audio_filename, "rb") as audio_file:
# transcribe the audio file
transcription = openai.Audio.transcribe("whisper-1", audio_file) # whisper-1 is the model name
return transcription
if __name__ == "__main__":
transcription = get_openai_api_transcription("7601-291468-0006.wav")
print(transcription.get("text"))As you can see, using the OpenAI API is ridiculously simple, we use the openai.Audio.transcribe() method to perform speech recognition. The returning object is an OpenAIObject in which we can extract the text using the Python dict's get() method. Here's the output:
His abode, which he had fixed at a bowery or country seat at a short distance from the city, just at what is now called Dutch Street, soon abounded with proofs of his ingenuity —patent smoke-jacks that required a horse to work them, Dutch ovens that roasted meat without fire, carts that went before the horses, weathercocks that turned against the wind, and other wrong-headed contrivances that astonished and confounded all beholders.For larger audio files, we can simply use the get_large_audio_transcription_on_silence() above function, but replace the transcribe_audio() with the get_openai_api_transcription() function, you can get the complete code here.
Using 🤗 Transformers
Whisper is a general-purpose open-source speech recognition transformer model, trained on a large dataset of diverse weakly supervised audio (680,000 hours) on multiple languages on different tasks (speech recognition, speech translation, language identification, and voice activity detection).
Whisper models demonstrate a strong ability to adjust to different datasets and domains without the necessity for fine-tuning. As in the Whisper paper: "The goal of Whisper is to develop a single robust speech processing system that works reliably without the need for dataset-specific fine-tuning to achieve high-quality results on specific distributions".
To get started, let's install the required libraries for this:
$ pip install transformers==4.28.1 soundfile sentencepiece torchaudio pydubWe will be using the Huggingface Transformers library to load our Whisper models. Please check this tutorial if you want a more detailed guide on this.
Open up a new Python file named transformers_whisper.py, and add the following code:
from transformers import WhisperProcessor, WhisperForConditionalGeneration
import torch
import torchaudio
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# whisper_model_name = "openai/whisper-tiny.en" # English-only, ~ 151 MB
# whisper_model_name = "openai/whisper-base.en" # English-only, ~ 290 MB
# whisper_model_name = "openai/whisper-small.en" # English-only, ~ 967 MB
# whisper_model_name = "openai/whisper-medium.en" # English-only, ~ 3.06 GB
whisper_model_name = "openai/whisper-tiny" # multilingual, ~ 151 MB
# whisper_model_name = "openai/whisper-base" # multilingual, ~ 290 MB
# whisper_model_name = "openai/whisper-small" # multilingual, ~ 967 MB
# whisper_model_name = "openai/whisper-medium" # multilingual, ~ 3.06 GB
# whisper_model_name = "openai/whisper-large-v2" # multilingual, ~ 6.17 GBWe have imported the WhisperProcessor for processing the audio before inference, and also WhisperForConditionalGeneration to perform speech recognition on the processed audio.
You can see the different model versions and sizes along with their size. The bigger the model, the better the transcription, so keep that in mind. For demonstration purposes, I'm going to use the smallest one, openai/whisper-tiny; it should work on a regular laptop. Let's load it:
# load the model and the processor
whisper_processor = WhisperProcessor.from_pretrained(whisper_model_name)
whisper_model = WhisperForConditionalGeneration.from_pretrained(whisper_model_name).to(device)Now let's make the function responsible for loading an audio file:
def load_audio(audio_path):
"""Load the audio file & convert to 16,000 sampling rate"""
# load our wav file
speech, sr = torchaudio.load(audio_path)
resampler = torchaudio.transforms.Resample(sr, 16000)
speech = resampler(speech)
return speech.squeeze()Of course, the sampling rate should be fixed and only a 16,000 sampling rate works for Whisper, if you don't do this processing step, you'll have very weird and wrong transcriptions in the end.
Next, let's write the inference function:
def get_transcription_whisper(audio_path, model, processor, language="english", skip_special_tokens=True):
# resample from whatever the audio sampling rate to 16000
speech = load_audio(audio_path)
# get the input features from the audio file
input_features = processor(speech, return_tensors="pt", sampling_rate=16000).input_features.to(device)
# get the forced decoder ids
forced_decoder_ids = processor.get_decoder_prompt_ids(language=language, task="transcribe")
# generate the transcription
predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)
# decode the predicted ids
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=skip_special_tokens)[0]
return transcriptionInside this function, we're loading our audio file, doing preprocessing, and generating the transcription before decoding the predicted IDs. Again, if you want more details, check this tutorial.
Let's try the function:
if __name__ == "__main__":
english_transcription = get_transcription_whisper("7601-291468-0006.wav",
whisper_model,
whisper_processor,
language="english",
skip_special_tokens=True)
print("English transcription:", english_transcription)
arabic_transcription = get_transcription_whisper("arabic-audio.wav",
whisper_model,
whisper_processor,
language="arabic",
skip_special_tokens=True)
print("Arabic transcription:", arabic_transcription)
spanish_transcription = get_transcription_whisper("cual-es-la-fecha-cumple.mp3",
whisper_model,
whisper_processor,
language="spanish",
skip_special_tokens=True)
print("Spanish transcription:", spanish_transcription)Output:
English transcription: His abode, which he had fixed at a bow-ray, or country seat, at a short distance from the city, just that what is now called Dutch Street, soon abounded with proofs of his ingenuity, patent-smoked jacks that required a horse to work them, Dutch ovens that roasted meat without fire, carts that went before the horses, weathercocks that turned against the wind, and other wrong-headed
Arabic transcription: .نرقلا اذه لاوط عافترالا يف ةبوترلا تايوتسمو ةرارحلا تاجرد رمتست نأ مولعلل ةينيصلا ةيميداكألا يف تبتلا ةبضه ثاحبأ دهعم هدعأ يذلا ريرقتلا حجرو
Spanish transcription: ¿Cuál es la fecha de tu cumpleaños?Transcribing Large Audio Files
For larger audio files, we can simply use the pipeline API offered by Huggingface to perform speech recognition:
from transformers import pipeline
import torch
import torchaudio
device = "cuda:0" if torch.cuda.is_available() else "cpu"
whisper_model_name = "openai/whisper-tiny" # multilingual, ~ 151 MB
def load_audio(audio_path):
"""Load the audio file & convert to 16,000 sampling rate"""
# load our wav file
speech, sr = torchaudio.load(audio_path)
resampler = torchaudio.transforms.Resample(sr, 16000)
speech = resampler(speech)
return speech.squeeze()
def get_long_transcription_whisper(audio_path, pipe, return_timestamps=True,
chunk_length_s=10, stride_length_s=1):
"""Get the transcription of a long audio file using the Whisper model"""
return pipe(load_audio(audio_path).numpy(), return_timestamps=return_timestamps,
chunk_length_s=chunk_length_s, stride_length_s=stride_length_s)
if __name__ == "__main__":
# initialize the pipeline
pipe = pipeline("automatic-speech-recognition",
model=whisper_model_name, device=device)
# get the transcription of a sample long audio file
output = get_long_transcription_whisper(
"7601-291468-0006.wav", pipe, chunk_length_s=10, stride_length_s=2)
print(f"Transcription: {output}")
print("="*50)
for chunk in output["chunks"]:
# print the timestamp and the text
print(chunk["timestamp"], ":", chunk["text"])Here's the output when running the script:
Transcription: {'text': ' His abode, which he had fixed at a bowray, or country seat, at a short distance from the city, just that what is now called Dutch Street, soon abounded with proofs of his ingenuity. Patent smoked jacks that required a horse to work them. Dutch ovens that roasted meat without fire, carts that went before the horses, weathercocks that turned against the
wind, and other wrong-headed quadrivances stonished and confounded all beholders.', 'chunks': [{'timestamp': (0.0, 12.56), 'text': ' His abode, which he had fixed at a bowray, or country seat, at a short distance from the city, just that what is now called Dutch Street, soon abounded'}, {'timestamp': (12.56, 15.5), 'text': ' with proofs of his ingenuity.'}, {'timestamp': (15.5,
34.64), 'text': ' Patent smoked jacks that required a horse to work them. Dutch ovens that roasted meat without fire, carts that went before the horses, weathercocks that turned against the wind, and other wrong-headed quadrivances stonished and confounded all beholders.'}]}
==================================================
(0.0, 12.56) : His abode, which he had fixed at a bowray, or country seat, at a short distance from the city, just that what is now called Dutch Street, soon abounded
(12.56, 15.5) : with proofs of his ingenuity.
(15.5, 34.64) : Patent smoked jacks that required a horse to work them. Dutch ovens that roasted meat without fire, carts that went before the horses, weathercocks that turned against the wind, and other wrong-headed quadrivances stonished and confounded all beholders.Conclusion
This guide provided a comprehensive tutorial on how to perform automatic speech recognition using Python. It covered three main approaches: using the SpeechRecognition library with Google Speech Recognition, leveraging the Whisper API from OpenAI, and performing inference directly on open-source Whisper models using the 🤗 Transformers library.
The tutorial included code examples for each method, demonstrating how to transcribe audio files, split large audio files into chunks, and utilize different models for improved transcription accuracy.
Additionally, the article showcased the multilingual capabilities of the Whisper model and provided a pipeline for transcribing large audio files using the 🤗 Transformers library.
You can get the complete code for this tutorial here.
Learn also: Speech Recognition using Transformers in Python.
Happy transcribing ♥
Let our Code Converter simplify your multi-language projects. It's like having a coding translator at your fingertips. Don't miss out!
View Full Code Explain My Code




Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!