Before we get started, have you tried our new Python Code Assistant? It's like having an expert coder at your fingertips. Check it out!
Introduction
With the advancement in computing power, machine learning and artificial intelligence have reached new heights. Natural Language Processing, a form of artificial intelligence that deals with human language and computer interactions, have become immensely popular both in research as well as in practical applications.
Natural Language Processing works on the text data collected from various sources such as the internet, interviews, writings, etc. The collected data is in a raw format containing undesirable characters, different forms of root words, extra spaces, etc. We can not feed the raw data to the NLP algorithms as it would reduce their efficiency to unacceptable levels.
Therefore, as much as we want to dive right into the algorithmic part of the NLP model, it is absolutely critical that we process the collected data in the correct format. This formatting of the data is commonly known as preprocessing. For the text data, the preprocessing often involves the procedures given below:
- Tokenization
- Stemming
- Lemmatization
This article discusses each of these procedures in detail. We would also discuss different ways of achieving each preprocessing procedure along with examples of code in Python.
Table of contents:
Tokenization
When we collect the data, it is almost always in the form of long, meaningful sentences containing words, special characters, and whitespaces. For a human being, it is easier to read the sentences, but for an algorithm, the sentence is often of no use, as most of the NLP algorithms work on the words rather than sentences. Therefore, it is necessary to convert the sentences or documents to words before feeding them to the algorithm.
Tokenization, as the name suggests, is the process of converting sentences or documents into a set of tokens or words. In a sentence, the words are often separated by whitespaces but can also be separated by special characters such as a comma, a hyphen, etc. In the tokenization process, we would break the sentences into words and store them as a list of words rather than a continuous sentence.

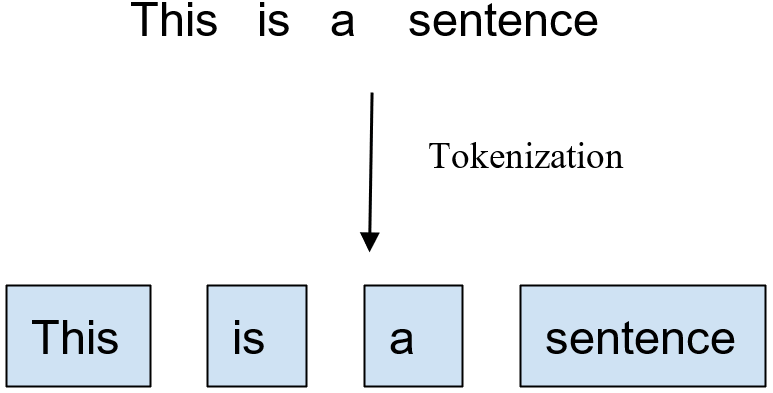
There are different ways to achieve the task of tokenization in Python. Let us discuss each of these ways one by one.
Tokenization by Splitting the Sentence by Whitespaces
As the words are often separated by whitespaces in a sentence, the easiest way to create tokens from a sentence is to split the sentence by whitespaces. You can traverse the sentence and separate each word by detecting the whitespaces between them.
Python provides a built-in function split() to separate sentences by character. The function accepts a character argument and uses this character to split the sentences.
For example:
- If you pass a whitespace character, it would return a list containing words (or sentences) that are separated by whitespaces in the original sentence.
- And if you pass a comma, it would return a list of words (or sentences) that are separated by a comma in the original sentence.
By default, the split() separates the sentence by whitespace. Let us understand the tokenization using split() with the code examples.
Example 1: Splitting by whitespace:
s = "Hello I am programmer"
lst = s.split()
print(lst)
Output:
['Hello', 'I', 'am', 'programmer']Example 2: Splitting by comma.
s = "Hello, I am programmer"
lst = s.split(',')
print(lst)
Output:
['Hello', ' I am programmer']Example 3: In this example, code reads a text file containing sentences and tokenizes each sentence.
Note that we would use the reviews.txt file for tokenization examples. You can create and save the same file on your local computer. The contents of the file are given below:
The restaurant has a good staff, good food, and a good environment.
It is a good place for family outings. Hospitable staff.
The staff is better than other places, but the food is okay.
People are great here. I loved this place.
def tokenize(file):
tok = []
f = open(file, 'r')
for l in f:
lst = l.split()
tok.append(lst)
return tok
tokens = tokenize('reviews.txt')
for e in tokens:
print(e)
Output:
['The', 'restaurant', 'has', 'a', 'good', 'staff,', 'good', 'food,', 'and', 'a', 'good', 'environment.']
['It', 'is', 'a', 'good', 'place', 'for', 'family', 'outings.', 'Hospitable', 'staff.']
['The', 'staff', 'is', 'better', 'than', 'other', 'places,', 'but', 'the', 'food', 'is', 'okay.']
['People', 'are', 'great', 'here.', 'I', 'loved', 'this', 'place.']
Disadvantages
However, there is a shortcoming of this method. The split() function does not remove special characters, such as commas, from the words that, in turn, can reduce the algorithm's efficiency.
Tokenization using TextBlob Library
TextBlob is a Python library widely used in processing text data for NLP. It provides several built-in functions to perform tasks such as tokenization, part-of-speech tagging, etc.
We can tokenize a sentence from our data using the TextBlob’s words object that returns a list of words. Note that the returned list is not a simple Python list; rather, it is a TextBlob Words object list.
The tokenization using TextBlob is simple, accurate, and overcomes the shortcoming of simple split() tokenization. Before using the TextBlob library, make sure that the textblob and nltk are installed on your computer. Otherwise, you can install the TextBlob using the simple pip command given below:
$ pip install textblob
$ pip install nltk
Once the libraries are installed, they are ready to use. Let us see the example code to tokenize the sentences from our file:
from textblob import TextBlob
def tokenize(file):
tok = []
f = open(file, 'r')
for l in f:
lst = TextBlob(l).words
tok.append(lst)
return tok
tokens = tokenize('reviews.txt')
for e in tokens:
print(e)
Output:
['The', 'restaurant', 'has', 'a', 'good', 'staff', 'good', 'food', 'and', 'a', 'good', 'environment']
['It', 'is', 'a', 'good', 'place', 'for', 'family', 'outings', 'Hospitable', 'staff']
['The', 'staff', 'is', 'better', 'than', 'other', 'places', 'but', 'the', 'food', 'is', 'okay']
['People', 'are', 'great', 'here', 'I', 'loved', 'this', 'place']
Note that the commas and periods are removed from the tokenized words.
Tokenization using NLTK Library
NLTK library is yet another popular library for NLP applications. It provides many tools to perform NLP operations, including preprocessing and tokenization. There are two different types of tokenizations that NTLK provides:
- Sentence tokenization: As the name suggests, sentence tokenization breaks the text into meaningful sentences rather than single words. This form can be especially useful in the applications such as sentiment analysis, where a paragraph needs to be broken into meaningful sentences to get the sentiment of each sentence.
- Word tokenization: This is the classic form of tokenization, where a text is broken into words. This article mainly focuses on this form of tokenization.
Let us understand each of them using examples. But before writing the code, make sure that the nltk library is installed. Otherwise, you can install it using the pip command given in the above section.
Example 1: Sentence tokenization using nltk:
from nltk import sent_tokenize
def tokenize(file):
tok = []
f = open(file, 'r')
for l in f:
lst = sent_tokenize(l)
tok.append(lst)
return tok
tokens = tokenize('reviews.txt')
for e in tokens:
print(e)
Output:
['The restaurant has a good staff, good food, and a good environment.']
['It is a good place for family outings.', 'Hospitable staff.']
['The staff is better than other places, but the food is okay.']
['People are great here.', 'I loved this place.']
Example 2: Word tokenization using nltk:
from nltk import word_tokenize
def tokenize(file):
tok = []
f = open(file, 'r')
for l in f:
lst = word_tokenize(l)
tok.append(lst)
return tok
tokens = tokenize('reviews.txt')
for e in tokens:
print(e)
Output:
['The', 'restaurant', 'has', 'a', 'good', 'staff', ',', 'good', 'food', ',', 'and', 'a', 'good', 'environment', '.']
['It', 'is', 'a', 'good', 'place', 'for', 'family', 'outings', '.', 'Hospitable', 'staff', '.']
['The', 'staff', 'is', 'better', 'than', 'other', 'places', ',', 'but', 'the', 'food', 'is', 'okay', '.']
['People', 'are', 'great', 'here', '.', 'I', 'loved', 'this', 'place', '.']
Disadvantages
The shortcoming of this method is that it includes special characters such as a comma and a period as separate tokens.
Byte-Pair Encoding Tokenizers
Byte-Pair encoding tokenizer is a new state-of-the-art tokenizing method. This is a supervised tokenizing mechanism as opposed to the other rule-based tokenizing mechanisms that we have seen till now.
Byte-pair encoding algorithm works as follows:
- The algorithm considers all the characters of the text as separate tokens.
- The next step is to find the most common characters that occur together and merge them into a single word.
- This process is repeated until the algorithm finds the number of tokens as needed.
BPE is a data compression algorithm that replaces the most frequent pairs of bytes in a given input with a single, unused byte. It is commonly used to encode text data in natural language processing tasks.
To implement BPE, the algorithm first creates a vocabulary of all the unique bytes in the input. It then iteratively identifies the most frequent pair of bytes in the input that is not already in the vocabulary and replaces it with a new, unused byte. This process is repeated until the desired vocabulary size is reached. The resulting vocabulary can be used to encode the input text as a sequence of bytes, with each byte representing a symbol in the vocabulary.
We will use the HuggingFace libraries to implement a Byte-Pair encoding tokenizer. If you do not have installed libraries, install them by using the below pip commands.
$ pip install huggingface
$ pip install tokenizers
Once you have installed the needed libraries, you would need a text dataset to train the BPE tokenizer model. For this, we can use the wikitext text file. You can download the wikitext file from the link given below:
https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zipOnce the file is downloaded, unzip it. It would be easier if you unzip it into the same folder as your program file folder.
Let us see the code, and let’s understand it.
Example: BPE tokenizer
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.trainers import BpeTrainer
tk = Tokenizer(BPE(unk_token="[UNK]"))
tr = BpeTrainer()
tk.pre_tokenizer = Whitespace()
f = [f"wikitext-103-raw\wiki.{s}.raw" for s in ["test", "train", "valid"]]
tk.train(f, tr)
tk.save("tokenizer-wiki.json")
We have instantiated a Tokenizer object and passed a BPE object to it. This tokenizer object will train the model for tokenizing the text. Note the unk_token parameter. At the places of special Unicode characters such as emojis, the tokenizer produces "[UNK]".
Although we can train the tokenizer after we have created a BpeTrainer object. But it might produce tokens that have more than one word. To ensure that only a single word token is generated as output, we have used a pre-tokenizer.
After the model is trained, it is better to save the model because training it each time would cost us a lot of time, and it is not a likable phenomenon.
Now let us fetch the saved model and tokenize our text data.:
from tokenizers import Tokenizer
tk = Tokenizer.from_file("tokenizer-wiki.json")
f = open('reviews.txt', 'r')
for l in f:
res = tk.encode(l.strip())
print(res.tokens)
Output:
['The', 'restaurant', 'has', 'a', 'good', 'staff', ',', 'good', 'food', ',', 'and', 'a', 'good', 'environment', '.']
['It', 'is', 'a', 'good', 'place', 'for', 'family', 'out', 'ings', '.', 'H', 'osp', 'itable', 'staff', '.']
['The', 'staff', 'is', 'better', 'than', 'other', 'places', ',', 'but', 'the', 'food', 'is', 'ok', 'ay', '.']
['People', 'are', 'great', 'here', '.', 'I', 'loved', 'this', 'place', '.']
HuggingFace's tokenizers library has several pre-trained tokenizers as well. These tokenizers save time to train our own tokenizers. You can get a pre-trained tokenizer, as given in the below example, without the need for training:
from tokenizers import Tokenizer
tk = Tokenizer.from_pretrained("bert-base-uncased")
Subword Tokenization
In the previous example, you might have noticed that some of the words in the BPE tokenizer’s output are meaningless. This happens because the word pair tokenization works on the principle of merging the frequently appearing words together without considering the fact that some words are split, producing meaningless results.
The subword tokenization takes care of this issue. It works on the principle that frequently occurring words should not be broken into smaller words. Rather, rarely occurring words should be broken into smaller and more meaningful words.
An advantage of subword tokenization is that the model can efficiently process words it has never seen. Also, the vocabulary size is limited.
The transformers library provides the pre-trained BertTokenizer which is a subword tokenizer. You can get the model in your code and use it directly. However, first, install the transformers library:
$ pip install transformersExample: Subword tokenization
from transformers import BertTokenizer
tk = BertTokenizer.from_pretrained('bert-base-uncased')
f = open('reviews.txt', 'r')
for l in f:
res = tk.tokenize(l.strip())
print(res)
Output:
['the', 'restaurant', 'has', 'a', 'good', 'staff', ',', 'good', 'food', ',', 'and', 'a', 'good', 'environment', '.']
['it', 'is', 'a', 'good', 'place', 'for', 'family', 'outing', '##s', '.', 'ho', '##sp', '##ita', '##ble', 'staff', '.']
['the', 'staff', 'is', 'better', 'than', 'other', 'places', ',', 'but', 'the', 'food', 'is', 'ok', 'ay', '.']
['people', 'are', 'great', 'here', '.', 'i', 'loved', 'this', 'place', '.']
WordPiece Tokenizer
The WordPiece tokenizer is a subword tokenization algorithm and is quite similar to the Byte Pair encoding tokenizer. However, it differs in the way it forms the tokens such that it does not choose the most frequent pair of characters that occur together. Rather, it chooses those character pairs that increase the likelihood of training data that is added to the vocabulary.
The HuggingFace’s tokenizers library provides a built-in word piece tokenizer with the name BertWordPieceTokenizer. It is simple to use but before using make sure that you have saved the pre-trained bert-base-uncased-vocab.txt model from the link given below.
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txtExample: Bert Word Piece Tokenizer
from tokenizers import BertWordPieceTokenizer
tk = BertWordPieceTokenizer("bert-word-piece-vocab.txt", lowercase=True)
f = open('reviews.txt', 'r')
for l in f:
res = tk.encode(l.strip())
print(res.tokens)
Output:
['[CLS]', 'the', 'restaurant', 'has', 'a', 'good', 'staff', ',', 'good', 'food', ',', 'and', 'a', 'good', 'environment', '.', '[SEP]']
['[CLS]', 'it', 'is', 'a', 'good', 'place', 'for', 'family', 'outing', '##s', '.', 'ho', '##sp', '##ita', '##ble', 'staff', '.', '[SEP]']
['[CLS]', 'the', 'staff', 'is', 'better', 'than', 'other', 'places', ',', 'but', 'the', 'food', 'is', 'okay', '.', '[SEP]']
['[CLS]', 'people', 'are', 'great', 'here', '.', 'i', 'loved', 'this', 'place', '.', '[SEP]']
Sentence Piece Tokenizer
At this point, you are familiar with many different tokenization approaches. However, the problem with all these approaches is that they assume that the words are separated using spaces. However, this might not be true for all languages.
The sentence piece tokenization approach treats the text as a raw stream rather than assuming whitespace to be a separating character. In this way, the whitespace is itself included in the character set.
In the transformers library, you can find a predefined and pre-trained tokenizer named XLNetTokenizer. It is a sentence-piece tokenizer. Let us understand it with the help of an example code.
Example: Sentence piece tokenizer
from transformers import XLNetTokenizer
tk = XLNetTokenize.from_pretrained('xlnet-base-cased')
f = open('reviews.txt', 'r')
for l in f:
res = tk.tokenize(l.strip())
print(res)
Output:
['_The', '_restaurant', '_has', '_a', '_good', '_staff', ',', '_good', '_food', ',', '_and', '_a', '_good', '_environment', '.']
['_It', '_is', '_a', '_good', '_place', '_for', '_family', '_out', 'ing', 's' '.', '_Ho', 's', 'pit', 'able', '_staff', '.']
['_The', '_staff', '_is', '_better', '_than', '_other', '_places', ',', '_but', '_the', '_food', '_is', '_okay', '.']
['_People', '_are', '_great', '_here', '.', '_I', '_loved', '_this', '_place', '.']
And with that, we have wrapped up tokenization.
Stemming
When humans express themselves, we use different forms of words as per language grammar. For example, the grammatically correct sentence is “I am playing”, where “playing” is different from its root form.
Stemming is a process of converting such words to their root form. Stemming does so by deleting the suffix and (or) prefix based on predefined rules. For example, ‘playing’ might be converted to ‘play’ after stemming.
Stemming can be an important preprocessing step before feeding the text to the NLP algorithm, as all the words originating from the same root words are converted to the same form. It increases the efficiency of the algorithm.
NLTK library provides us with two different algorithms for stemming. These are given below:
- Porter Stemmer: Porter stemmer uses a rule base to trim the prefixes or suffixes to bring the word to its root form. You can learn more about this algorithm here.
- Snowball Stemmer: Snowball stemmer is an improved form of porter stemmer. You can learn more about it here.
Let us see examples of Porter Stemmer and Snowball Stemmer.
Example 1: Porter Stemmer
from nltk.stem import PorterStemmer
word_lst = []
def stemmer(file):
stm_lst = []
stm = PorterStemmer()
f = open(file, 'r')
for l in f:
word_lst.append(l)
w = stm.stem(str(l.strip()))
stm_lst.append(w)
return stm_lst
stm_lst = stemmer('reviews.txt')
for i in range(len(word_lst)):
print(word_lst[i]+"-->"+stm_lst[i])
Output:
Stemming
-->stem
Outingly
-->outlingli
Perishable
-->perish
Civilization-->civil
Example 2: Snowball Stemmer
from nltk.stem.snowball import SnowballStemmer
word_lst = []
def stemmer(file):
stm_lst = []
stm = SnowballStemmer(language='english')
f = open(file, 'r')
for l in f:
word_lst.append(l)
w = stm.stem(str(l.strip()))
stm_lst.append(w)
return stm_lst
stm_lst = stemmer('reviews.txt')
for i in range(len(word_lst)):
print(word_lst[i]+"-->"+stm_lst[i])
Output:
Stemming
-->stem
Outingly
-->out
Perishable
-->perish
Civilization-->civil
Disadvantages of Stemming
- Since stemming is purely rule-based, it might suffer from over-stemming or under-stemming.
- Over-stemming: When the word is trimmed beyond the needed limit, you would term it over-stemming.
- Under-stemming: When the word is not trimmed enough to bring it to the root word, you would term it under-stemming.
- Stemming does not take care of how the word is being used. For example, a word might be present as a noun or verb, but stemming will result in the same word.
Lemmatization
The purpose of lemmatization is the same as that of stemming. However, as you might have noticed, stemming sometimes results in meaningless words. Moreover, it does not take care if the word is a noun, verb, or adjective. In turn, it might affect the efficiency of your NLP algorithm.
Lemmatization overcomes these drawbacks as it converts the words into a meaningful base word called the lemma. It takes vocabulary and morphological analysis into consideration rather than just trimming the words.
Lemmatization is more efficient and produces more accurate results but takes more time than stemming owing to the increased complexity of the algorithm.
NLTK library provides the WordNetLemmatizer to perform the lemmatization. The lemmatize() function accepts a word as an argument and returns its lemmatized form. Let us understand the WordNet lemmatizer with the help of code.
Example: WordNet lemmatizer
from nltk.stem import WordNetLemmatizer
word_lst = []
def lemmatizer(file):
lem_lst = []
lem = WordNetLemmatizer()
f = open(file, 'r')
for l in f:
word_lst.append(l.strip())
w = lem.lemmatize(str(l.strip()))
lem_lst.append(w)
return lem_lst
lem_lst = lemmatizer('reviews.txt')
for i in range(len(word_lst)):
print(word_lst[i]+"-->"+lem_lst[i])
Output:
workers-->worker
are-->are
working-->working
hard-->hard
and-->and
better-->better
on-->on
beeches-->beech
Part of Speech Tagging
As we discussed, words can mean differently in different forms. For example, a word can mean differently when it is used as a noun and when it is used as a verb. Part of Speech tagging enables us to identify the form of a word in a sentence.
NLTK has a built-in function pos_tag() that accepts a list of words and returns the POS tag of the word based on its properties, such as the first letter, previous word, next word, etc. Note that you would need the wordnet from nltk.corpus to generate the POS tag correctly.
The part of the speech tag is helpful in correctly lemmatizing the word. Some of the most common POS tags are given below.
- Noun
- Pronoun
- Verb
- Adjective
- Adverb
Let us see an example where we generate the POS tags for words and then pass them to WordNetLemmatizer to get the lemmatized word.
Example: POS Tags
import nltk
from nltk.corpus import wordnet
from nltk.stem import WordNetLemmatizer
word_lst = []
def lemmatizer(file):
lem_lst = []
lem = WordNetLemmatizer()
f = open(file, 'r')
for l in f:
word_lst.append(l.strip())
w = lem.lemmatize(str(l.strip()))
lem_lst.append(w)
return lem_lst
def generate_tag(w):
t = nltk.pos_tag([w])[0][1][0].upper()
dic = {
'N': wordnet.NOUN,
'V': wordnet.VERB,
'A': wordnet.ADJ,
'R': wordnet.ADV
}
return dic.get(t, wordnet.VERB)
lem_lst = lemmatizer('reviews.txt')
for i in range(len(word_lst)):
print(word_lst[i]+"-->"+lem_lst[i])
Output:
workers-->worker
are-->be
working-->work
hard-->hard
and-->and
better-->well
on-->on
beeches-->beech
You can clearly see the difference between the previous two outputs. We have tagged each word with the verb, and hence the lemmatizer() now return the root verb of each word. In this way, all words are now reduced to their verb base.
Comparison between Stemming and Lemmatization
- Stemming trims the prefixes and (or) suffixes from the words, while lemmatization takes care of the context of the words.
- Stemming is usually faster than lemmatization.
- Stemming is less efficient than lemmatization.
- You might want to use stems in the case of the large dataset, while if you need efficient pre-processing, you may go with lemmatization.
Conclusion
You have seen three basic pre-processing procedures that are necessary before feeding the text data to the NLP algorithm. Each of these procedures can be performed using many different methods. This article discussed the most popular methods of doing each of these tasks. While you can use the codes given in the articles directly, remember to make changes according to your environment and your needs.
You can get the complete codes for this tutorial here.
Learn also: Named Entity Recognition using Transformers and Spacy in Python.
Happy learning ♥
Ready for more? Dive deeper into coding with our AI-powered Code Explainer. Don't miss it!
View Full Code Improve My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!