Turn your code into any language with our Code Converter. It's the ultimate tool for multi-language programming. Start converting now!
Natural Language Processing (NLP) has evolved remarkably in recent decades. It has transformed from a niche field in artificial intelligence into a mainstream discipline, driving innovations in the healthcare, finance, and e-commerce sectors. NLP makes it possible for computers to read, decipher, understand, and make sense of human language in a valuable way. It powers the intelligent algorithms behind chatbots, voice assistants, automatic translators, and more.
Table of Contents
- Evaluating NLP: The Crucial Role of Evaluation Metrics
- ROUGE Score: A Premier Evaluation Metric
- ROUGE Score Components: Peering into the Details
- Setting Up the Environment for Python Implementation
- The Role of the ROUGE Score in Machine Translation and Text Summarization
- Conclusion
Evaluating NLP: The Crucial Role of Evaluation Metrics
Evaluation metrics in NLP serve as the yardstick for measuring the success of these sophisticated algorithms. They quantify precision, recall, and other relevant statistical information that provides insight into the effectiveness of an NLP model. These metrics also help fine-tune the models by revealing areas requiring improvement.
ROUGE Score: A Premier Evaluation Metric
Among the ensemble of evaluation metrics, the ROUGE Score is prominent. Standing for Recall-Oriented Understudy for Gisting Evaluation, the ROUGE Score is the lynchpin of automatic text summarization, a fascinating subfield of NLP.
Text summarization is the art of distilling the essence of text content. It involves creating coherent and concise summaries of longer documents while retaining key information. The ROUGE Score is the go-to metric for assessing the quality of such machine-generated summaries.
ROUGE Score Components: Peering into the Details
The ROUGE Score has three main components: ROUGE-N, ROUGE-L, and ROUGE-S. Each ROUGE score component offers a different perspective on the quality of the system-generated summary, considering different aspects of language and sentence structure. This is why a combination of these measures is usually used in evaluating system outputs in NLP tasks.
ROUGE-N
ROUGE-N is a component of the ROUGE score that quantifies the overlap of N-grams, contiguous sequences of N items (typically words or characters), between the system-generated summary and the reference summary. It provides insights into the precision and recall of the system's output by considering the matching N-gram sequences.
ROUGE-L
ROUGE-L, another component of the ROUGE Score, calculates the Longest Common Subsequence (LCS) between the system and reference summaries. Unlike N-grams, LCS measures the maximum sequence of words (not necessarily contiguous) that appear in both summaries. It offers a more flexible similarity measure and helps capture shared information beyond strict word-for-word matches.
ROUGE-S
ROUGE-S focuses on skip-bigrams. A skip-bigram is a pair of words in a sentence that allows for gaps or words in between. This component identifies the skip-bigram overlap between the system and reference summaries, enabling the assessment of sentence-level structure similarity. It can capture paraphrasing relationships between sentences and provide insights into the system's ability to convey information with flexible word ordering.
Each component provides a different perspective and helps comprehensively evaluate the text summaries' quality. With a solid understanding of the ROUGE Score's components, we can dive into their practical implementation using Python.
Setting Up the Environment for Python Implementation
To implement the ROUGE Score in Python, you must ensure you have the right tools and libraries. In this case, you'll need the rouge_score library. You can install it using pip, Python's package installer. Open your terminal or command prompt and run the following command:
$ pip install rouge-score
Step-by-step Guide to Implementing the ROUGE Score in Python
Once the rouge_score library is installed, you can start calculating the ROUGE scores.
Import the Necessary Library
First, you need to import the rouge_scorer from the rouge_score package. Here's how you can do it:
from rouge_score import rouge_scorerInitialize the RougeScorer
The next step is to initialize the RougeScorer. You need to specify which types of ROUGE scores you are interested in. For instance, if you want to calculate ROUGE-1, ROUGE-2, and ROUGE-L scores, you would initialize the scorer like this:
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)Calculate the ROUGE Scores
Now that you have the scorer ready, you can calculate the ROUGE scores for a given pair of candidates and reference summaries. Here's how you can do it:
candidate_summary = "the cat was found under the bed"
reference_summary = "the cat was under the bed"
scores = scorer.score(reference_summary, candidate_summary)
for key in scores:
print(f'{key}: {scores[key]}')Output:
rouge1: Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923)
rouge2: Score(precision=0.6666666666666666, recall=0.8, fmeasure=0.7272727272727272)
rougeL: Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923)Calculate ROUGE Scores for Multiple References
Sometimes, you may have multiple reference summaries for a single candidate summary. In such cases, you can calculate the ROUGE scores for each reference separately and store them. Here's how you can do it:
candidate_summary = "the cat was found under the bed"
reference_summaries = ["the cat was under the bed", "found a cat under the bed"]
scores = {key: [] for key in ['rouge1', 'rouge2', 'rougeL']}
for ref in reference_summaries:
temp_scores = scorer.score(ref, candidate_summary)
for key in temp_scores:
scores[key].append(temp_scores[key])
for key in scores:
print(f'{key}:\n{scores[key]}')When you run the code, you should see an output that looks something like this:
rouge1:
[Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923), Score(precision=0.7142857142857143, recall=0.8333333333333334, fmeasure=0.7692307692307692)]
rouge2:
[Score(precision=0.6666666666666666, recall=0.8, fmeasure=0.7272727272727272), Score(precision=0.3333333333333333, recall=0.4, fmeasure=0.3636363636363636)]
rougeL:
[Score(precision=0.8571428571428571, recall=1.0, fmeasure=0.923076923076923), Score(precision=0.5714285714285714, recall=0.6666666666666666, fmeasure=0.6153846153846153)]Following these steps, you can efficiently compute the ROUGE scores for any candidate and reference summaries. The ROUGE scores will give you a quantified understanding of how well your model generates summaries or translations.
The Role of the ROUGE Score in Machine Translation and Text Summarization
In the complex realm of NLP, the ROUGE score has carved out a unique niche for itself. Its central value is found in two pivotal NLP fields: machine translation and text summarization.
When you delve into machine translation and text summarization, you quickly realize that the quality of the output hinges upon how well it parallels human-made translations or summaries. That's where the ROUGE score comes into play. It allows the comparison of machine-generated output with human-made references to evaluate the accuracy and quality of the machine's performance.
Precision and Recall: The Twin Pillars of the ROUGE Score
The essence of the ROUGE Score can be distilled into two core metrics: precision and recall. The ROUGE Score quantitatively assesses machine translation and text summarization models by calculating these two parameters.
To put it into context, a high recall value, ideally close to 1, implies that the content of the machine-generated output aligns closely with the human-made reference. It signifies the model's proficiency in capturing relevant information:

Conversely, a high precision value suggests that the words or phrases churned out by the machine translation or submodel are primarily accurate. It denotes the model's capability to produce relevant output, minimizing false positives:
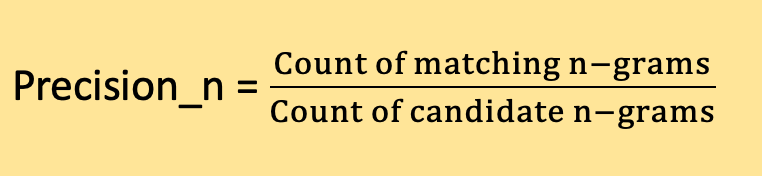
Fine-tuning Models with the ROUGE Score
By providing these key metrics, the ROUGE Score contributes significantly to fine-tuning of machine translation and text summarisation models. It offers tangible performance evaluation measures, leading to continuous improvement and refinement of these models. The result is the onward propulsion of the field of NLP, with ever-increasing accuracy and efficiency.
Conclusion
In conclusion, the ROUGE score holds immense significance in NLP. It is a powerful tool for evaluating the performance of machine translation and text summarisation models, providing crucial insights into the quality and accuracy of machine-generated outputs.
What sets the ROUGE score apart is its Python implementation. It empowers developers and researchers to calculate and interpret these scores with ease, making the process of gauging model performance both practical and effective.
The ROUGE score remains at the heart of progress as NLP continues to evolve. It drives advancements in developing increasingly accurate and efficient NLP models. Truly, understanding the ROUGE Score's workings and implementation is a linchpin to pioneering developments in this thrilling field of study.
Once you've mastered these concepts, you'll want to prepare for real interview scenarios, check out 25 Machine Learning Interview Questions for 2026 to see how companies actually test this knowledge
Here are some related tutorials:
Check the complete code here.
Happy learning ♥
Take the stress out of learning Python. Meet our Python Code Assistant – your new coding buddy. Give it a whirl!
View Full Code Auto-Generate My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!